Wikipedia talk:Manual of Style/Accessibility/Archive 6
| This is an archive of past discussions about Wikipedia:Manual of Style. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |
| Archive 1 | ← | Archive 4 | Archive 5 | Archive 6 | Archive 7 | Archive 8 | → | Archive 10 |
layout of the article germanium
I have received this comment about the article from the FAC director: layout issues abound, and they are too non-standard for me to sort. Please go to the WP:ACCESS talk page and inquire if this layout is accessible. Any opinions? Nergaal (talk) 02:02, 2 October 2008 (UTC)
- Thanks Nergaal (but I'm not the FAC director, I'm the FAC delegate :-) I'll watchlist for the response. SandyGeorgia (Talk) 02:04, 2 October 2008 (UTC)
- Which layout issues? Or have they been fixed by now? I don't notice any difference with my screen reader. Graham87 07:07, 2 October 2008 (UTC)
- So the way all of the elements and images are laid out in the early sections processes fine through the screen reader? They're quite a jumble on my screen. Just checking, as I can't determine how they would flow through. SandyGeorgia (Talk) 07:19, 2 October 2008 (UTC)
- Actually, not the top, the middle of the History section. SandyGeorgia (Talk) 07:20, 2 October 2008 (UTC)
- Yes, the image layout before the table in the history section reads fine because screen readers read everything linearly. The only tghing needed for images to work with screen readers is a caption - it doesn't matter where their positioned. I'm not sure how a non-standard layout would look with screen magnifiers though. Graham87 08:33, 2 October 2008 (UTC)
- Actually, not the top, the middle of the History section. SandyGeorgia (Talk) 07:20, 2 October 2008 (UTC)
- So the way all of the elements and images are laid out in the early sections processes fine through the screen reader? They're quite a jumble on my screen. Just checking, as I can't determine how they would flow through. SandyGeorgia (Talk) 07:19, 2 October 2008 (UTC)
- Which layout issues? Or have they been fixed by now? I don't notice any difference with my screen reader. Graham87 07:07, 2 October 2008 (UTC)
- The reviewers could get a first-cut simulation of a screen magnifier by using their browsers' "enlarge" facility - CTRL+ in FF and Opera. May not work in IE, as last time I looked IE failed the WCAG guideline that users should be able to enlarge even if the page specifies absolute font size (px). The other thing to watch out for is dependence on window width - complex layouts that work in maximised windows on wide (16:10) screens may not work in non-maximised windows or on the increasingly rare "standard" screens (4:3). -- Philcha (talk) 08:52, 2 October 2008 (UTC)
Equilibrium symbol
There is an ongoing accessibility problem in many chemistry articles about the double arrow used to represent a chemical equilibrium. We can either use TeX to render this as or Unicode to render this as ⇌. Inline TeX seems bad for users of screenreaders (and doesn't look wonderful on the page), but switching to Unicode will leave many readers with little boxes or question marks on their screen (at least the last time we tested it across different browsers). There's obviously a limit to how far we can avoid using this symbol in articles about chemistry, so I am interested in any comments from users at this page as to the relative merits of the current solutions. Physchim62 (talk) 12:20, 11 October 2008 (UTC)

- The TeX version sounds bad with screen readers (they read the raw TeX), but at least it's possible to figure out what the symbol is and distinguish it from other symbols. With the unicode, unless the user has defined the symbol as "double arrow" or similar in their settings file, it won't be read at all. Therefore I slightly prefer the use of TeX in this case. Graham87 14:53, 11 October 2008 (UTC)
- Would it help readers to provide downloadable or copyable character glossaries for IPA, math, etc? I suppose not the casual reader, but this could be generally helpful to anyone who has a persistent interest in whatever subject, in Wikipedia and elsewhere. —Michael Z. 2008-10-14 18:52 z
- I think that's an excellent idea, not only for readers but for editors as well. Physchim62 (talk) 20:19, 14 October 2008 (UTC)
- This sounds like an instance where having the
title=attribute enabled would be of some help... ~ L'Aquatique[talk] 20:28, 14 October 2008 (UTC)
- This sounds like an instance where having the
- I think that's an excellent idea, not only for readers but for editors as well. Physchim62 (talk) 20:19, 14 October 2008 (UTC)
- Would it help readers to provide downloadable or copyable character glossaries for IPA, math, etc? I suppose not the casual reader, but this could be generally helpful to anyone who has a persistent interest in whatever subject, in Wikipedia and elsewhere. —Michael Z. 2008-10-14 18:52 z
- You can define alt and style attributes in math tags, e.g. A + B C - D — Dispenser 02:41, 20 October 2008 (UTC)
- That reads fine with screen readers under the default math settings. At this point it doesn't matter to me whether we use TX with the alt tags or the image. Graham87 08:45, 20 October 2008 (UTC)
- I think I prefer the image- at least in the browser I'm viewing right now (firefox on xp with low screen resolution) the TeX version is really blurry. I'll have to check it with other systems. ~ L'Aquatique[talk] 18:14, 22 October 2008 (UTC)
- That reads fine with screen readers under the default math settings. At this point it doesn't matter to me whether we use TX with the alt tags or the image. Graham87 08:45, 20 October 2008 (UTC)
Arbitrary section break:Use image?
How about using a small image instead? For example:
- 2H2 + O2 equilibrium symbol 2H2O
{kind=link}
- Wikicode:
2H<sub>2</sub> + O<sub>2</sub> [[Image:Rightleftharpoons.gif|16px|equilibrium symbol]] 2H<sub>2</sub>O
Note that the image has a title ("equilibrium symbol") which is included in the HTML code as the title for the link and as the alt text for the image:
- [...]
<a href="/wiki/Image:Rightleftharpoons.gif" class="image" title="equilibrium symbol"><img alt="equilibrium symbol" src="http://upload.wikimedia.org/wikipedia/commons/2/2d/Rightleftharpoons.gif" width="16" height="19" border="0" /></a>[...]
This has the advantage that we could produce an image which looks decent, unlike the TeX rendering and Unicode character in many fonts, and which can be displayed by any graphical browser, unlike the Unicode character. A disadvantage is that images in most browsers are not resizeable, but the same problem applies to the Tex version. Another problem is that the link pointing to the image information page is annoying (and I don't know how screen readers will deal with it). --Itub (talk) 15:10, 17 October 2008 (UTC)
- Screen readers will display the image link on its own line. However I think the image is the best option because the image will display in all browsers and the alt text will be displayed by all screen readers. Graham87 15:26, 17 October 2008 (UTC)
- I think you are right. Of course, if we go with the image idea, I'd suggest creating a template to make inputing the image easier, and to standardize the alt text. --Itub (talk) 15:51, 17 October 2008 (UTC)
- Sounds good to me. Graham87 16:03, 17 October 2008 (UTC)
- I would suggest using this code for the current template {{eqm}} in the medium term, once we've had a chance to test it at WP:CHEMS. As an image it should be an SVG for example, and we would need to fit it to usual text sizes. Nothing major or impossible, IMHO. Physchim62 (talk) 16:20, 17 October 2008 (UTC)
- There was a template called {{eqm}} that displayed the Unicode character, which was not used in many pages. I have boldly modified it to use the image instead. Let's test it here: A ⇌ B. We may need a better image, though. The current one sits too low in the line, with the bottom arrow showing as a descender. --Itub (talk) 16:22, 17 October 2008 (UTC)
- That's easily fixable. I'm going on a plane trip today, I'll make an .svg version that sits higher inline while I'm sitting around. I'll have it uploaded tonight- ~ L'Aquatique[talk] 17:35, 17 October 2008 (UTC)
- 2SO2 + O2
 2SO3. All right, not bad. I just need to shorten the horizontal lines a little bit and it should be good. ~ L'Aquatique[talk] 21:54, 17 October 2008 (UTC)
2SO3. All right, not bad. I just need to shorten the horizontal lines a little bit and it should be good. ~ L'Aquatique[talk] 21:54, 17 October 2008 (UTC)
- Okay, all uploaded. What do you guys think? ⇌ (you may need to purge your cache to see the latest version) ~ L'Aquatique[talk] 22:01, 17 October 2008 (UTC)
- 2SO2 + O2
- That's easily fixable. I'm going on a plane trip today, I'll make an .svg version that sits higher inline while I'm sitting around. I'll have it uploaded tonight- ~ L'Aquatique[talk] 17:35, 17 October 2008 (UTC)
- There was a template called {{eqm}} that displayed the Unicode character, which was not used in many pages. I have boldly modified it to use the image instead. Let's test it here: A ⇌ B. We may need a better image, though. The current one sits too low in the line, with the bottom arrow showing as a descender. --Itub (talk) 16:22, 17 October 2008 (UTC)
I think your harpoons are inverted? The "common" use is rightleftharpoons, not leftrightharpoons. --Rifleman 82 (talk) 05:33, 18 October 2008 (UTC)
- Yes, it is backwards, and I think it could look better if the lines were a little bit closer. But in terms of position it looks good. --Itub (talk) 06:32, 18 October 2008 (UTC)
- So... A + B ⇌ C + D. Well first I second/third Rifleman 82, the arrows need inverting in the plane of the page. On Safari (3.1.2) w/1280*800 (and a couple of lower resolutions) it looks fine. However looking at the previewed eqn I wrote out the bottom arrow could do with being brought up a little, as it still appears to hang below text line. I'll check it in Firefox too --EDIT--Firefox (2.0.0.13): Looks good, but bottom arrow still too low. --WhirlwindChemist (talk) 09:56, 18 October 2008 (UTC)
- Haha, that's embarrassing, I'll flip it as soon as I get the chance. Here's the problem, though- as far as making it sit higher inline, that may be difficult since when you save a file as an .svg, you don't get to define the window size, it just automatically saves it as closely-cropped to the edges as possible. It may be better to simply make a .png- large enough to be relatively resizable... ~ L'Aquatique[talk] 16:32, 18 October 2008 (UTC)
- Okie dokie, so what I've done is made a .png version, which is not a vector image and thus is not infinitely resizable, however it is 920 × 676 pixels which is big- I can't imagine a circumstance where we would need a chemical equilibrium symbol bigger than that! A + B
 C - D . Unfortunately, as you may have noticed... the lines are now too close together, and also I'm thinking a little too thick. Well, I guess I'm back to the photoshop drawing board... ~ L'Aquatique[talk] 00:52, 19 October 2008 (UTC)
C - D . Unfortunately, as you may have noticed... the lines are now too close together, and also I'm thinking a little too thick. Well, I guess I'm back to the photoshop drawing board... ~ L'Aquatique[talk] 00:52, 19 October 2008 (UTC)
- Okie dokie, so what I've done is made a .png version, which is not a vector image and thus is not infinitely resizable, however it is 920 × 676 pixels which is big- I can't imagine a circumstance where we would need a chemical equilibrium symbol bigger than that! A + B
- Haha, that's embarrassing, I'll flip it as soon as I get the chance. Here's the problem, though- as far as making it sit higher inline, that may be difficult since when you save a file as an .svg, you don't get to define the window size, it just automatically saves it as closely-cropped to the edges as possible. It may be better to simply make a .png- large enough to be relatively resizable... ~ L'Aquatique[talk] 16:32, 18 October 2008 (UTC)
- So... A + B ⇌ C + D. Well first I second/third Rifleman 82, the arrows need inverting in the plane of the page. On Safari (3.1.2) w/1280*800 (and a couple of lower resolutions) it looks fine. However looking at the previewed eqn I wrote out the bottom arrow could do with being brought up a little, as it still appears to hang below text line. I'll check it in Firefox too --EDIT--Firefox (2.0.0.13): Looks good, but bottom arrow still too low. --WhirlwindChemist (talk) 09:56, 18 October 2008 (UTC)
- Testing a new version: A
 B. I think the best will be to create a png in the exact resolution we want to use, because otherwise the rescaling can introduce some blurriness. --Itub (talk) 07:00, 19 October 2008 (UTC)
B. I think the best will be to create a png in the exact resolution we want to use, because otherwise the rescaling can introduce some blurriness. --Itub (talk) 07:00, 19 October 2008 (UTC)
Arbitrary section break:SVG or PNG
- Think we should stick with SVG for scalability? Wishlist: top heavy or bottom heavy eqm arrows to denote that equilibrium lies more to the right or left? --Rifleman 82 (talk) 08:50, 19 October 2008 (UTC)
- No, I'm convinced by the arguments for PNG given above: an SVG image in this case is always going to sit too low on the line. Some of the blurriness would be removed if you made the dimensions of the PNG image an exact multiple of 16 (the pixel size we're testing at). I actually quite like Aquatique's last version with the lines slightly closer together. Physchim62 (talk) 10:25, 19 October 2008 (UTC)
- It's not true that an SVG will always sit too low. An SVG image can be contained in a "page" that is larger than the visible part! --Itub (talk) 11:51, 19 October 2008 (UTC)
- After purging your cache, tell me if you like this: A + B
 D - C. It's still a little low, but it doesn't show as a descender- at least for me. ~ L'Aquatique[talk] 17:41, 19 October 2008 (UTC)
D - C. It's still a little low, but it doesn't show as a descender- at least for me. ~ L'Aquatique[talk] 17:41, 19 October 2008 (UTC)
- After purging your cache, tell me if you like this: A + B
- It's not true that an SVG will always sit too low. An SVG image can be contained in a "page" that is larger than the visible part! --Itub (talk) 11:51, 19 October 2008 (UTC)
- Looks pretty good to me! --Itub (talk) 18:22, 19 October 2008 (UTC)
- Me too! Let's just try scaling it:
- 16px + 0pt + A + B 16px − 0pt + A + B
- 15px + 0pt + A + B
 15px − 0pt + A + B
15px − 0pt + A + B - 14px + 0pt + A + B
 14px − 0pt + A + B
14px − 0pt + A + B
- 16px + 0pt + A + B
- The fifteen pixel version would be perfect, if it wasn't for the blurring. Physchim62 (talk) 18:44, 19 October 2008 (UTC)
- It shouldn't be blurring like that, it's a vector image. That's really strange. ~ L'Aquatique[talk] 22:30, 19 October 2008 (UTC)
- It's because, with SVG, you set a fixed width for the line: if that width doesn't translate into an integer number of pixels, you will get blurring. Let's try:
- A + B
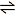 C − D
C − D
- A + B
- You see that the PNG image is nice and sharp, because I touched it up by hand at the exact scale I wanted it (based on the Unicode character in Arial). Physchim62 (talk) 23:13, 19 October 2008 (UTC)
- I still prefer using an .svg version because when font size is bigger, it will still be useful. Is there consensus that it 16px is too big? I thought it was just right. ~ L'Aquatique[talk] 23:22, 19 October 2008 (UTC)
- The problem is that users won't be able to change the size of the image to fit the font size, so there's no advantage in having SVG in {{eqm}}. The SVG image is still useful to have around though! Physchim62 (talk) 23:37, 19 October 2008 (UTC)
[unindent]Well, I could write in a switch to the template that would allow you to define your own size. It would be like... {{eqm|size=50}} would render ![]() , but to not specify a size, i.e. just leave it {{eqm}} would render it at the default size, 16 px. ~ L'Aquatique[talk] 23:47, 19 October 2008 (UTC)
, but to not specify a size, i.e. just leave it {{eqm}} would render it at the default size, 16 px. ~ L'Aquatique[talk] 23:47, 19 October 2008 (UTC)
- Thank's for the section breaks! We could easily put a switch in there, but I'm not sure it would ever be used. What we can't do is have the image appear bigger for people who read with larger default character sizes but normal size for the majority of users, not without a lot of fancy coding within MediaWiki. For any given wikicode, the HTML output is fixed. Physchim62 (talk) 23:55, 19 October 2008 (UTC)
- Right, unfortunately I think we will have to do without that. There are enough positives to using an image that I think it outweighs these few negatives. Whether we use the png or svg doesn't really matter a whole lot to me.
- As a side note, I left a notification a while back at WikiProject Chemistry that one of them should come over and okay this. I suppose silence implies content here. Once we agree on an image I guess next step is to start putting it into practice. A buddy of mine runs a bot that would be easily programmed to replace all instances of the unicode character and TeX markup with {{eqm}}. ~ L'Aquatique[talk] 00:05, 20 October 2008 (UTC)
- Itub and Rifleman are both very active chemistry editors; I do a bit myself from time to time as well ;) Physchim62 (talk) 00:13, 20 October 2008 (UTC)
- Perfect! ~ L'Aquatique[talk] 00:19, 20 October 2008 (UTC)
- Itub and Rifleman are both very active chemistry editors; I do a bit myself from time to time as well ;) Physchim62 (talk) 00:13, 20 October 2008 (UTC)
Help:Accessibility
Help:Accessibility is supposed to provide practical advice to readers about issues related to accessibility. So far, it says that you can adjust the size of the text in Firefox -- and that's it. Would someone like to expand it? WhatamIdoing (talk) 17:28, 14 October 2008 (UTC)
Script for screen readers like Fire Vox
Hi,
I'm interested in improving the accessibility of Wikipedia's articles, so I thought I'd say "hello" and ask for your help with a toy project. I've been experimenting with a script to strip the wikilinks out of Wikipedia articles so that the prose reads more smoothly in free screen readers such as Fire Vox. Would you help me to improve it? I think hearing articles read smoothly would help both the readers and writers of Wikipedia's articles.
You can try out the script by adding "importScript('User:Proteins/striparticlelinks.js');" to your monobook.js subpage under your user name, as you can see at my own user page. The script adds a tab at the top of your page entitled "strip links"; the tab is to the right of the "watch" tab. Once you put the script on your monobook.js page, you can invoke the script in any article by clicking that tab or by typing "alt-shift-s". An "alert" window will appear to let you know that the script worked and tell you how many links it removed from the article. It usually takes a few seconds for the script to complete its work, about 1 second per hundred links.
After installing Fire Vox, I've tried the script out on various Featured Articles, where it seems to have worked well. It's fun to hear articles such as Domestic sheep read aloud! But I'm new to accessibility concerns, and your suggestions for making the script more useful would be helpful. Perhaps the problem of reading Wikipedia articles smoothly has already been solved by more sophisticated screen readers than Fire Vox, but that would be helpful for me to know as well. No use re-inventing the wheel!
The script mainly strips out the wikilinks from the prose sections of the main article. It preserves the navigational links, the "See also" links, the edit links for each section, the reference links, the external links, and similar types of links. If you'd like to keep or eliminate other types of links , please let me know. I noticed that image captions get read twice; should I eliminate that? Thank you, Proteins (talk) 23:41, 14 October 2008 (UTC)
- NonVisual Desktop Access is a much more complex free screen reader. Most blind people have gotten used to arrowing past links, because on most screen readers, they appear on their own line. But the script would be useful for beginners or those who don't link arrowing past ten million links. I don't have much time now, so I can't check it out properly yet. Graham87 01:45, 15 October 2008 (UTC)
Thanks for considering the script and the tip about NVDA, which does seem like a more powerful screen reader. I've downloaded it, but I'm also interested in Fire Vox, because it works across operating systems and seems easier for beginners to use. I'm hoping that the script will help editors improve their article writing by hearing what they've written.
I've made some improvements to the script since yesterday. I think I've fixed that bug 11555 you mentioned above, the one in which the section heading and its edit button occur in the wrong order. I also hacked a solution to the doubled reading of captions, and introduced image numbering. Please feel free to offer other suggestions when you find the time to try out the script. Thank you, Proteins (talk) 16:42, 15 October 2008 (UTC)
- The script works very well, though is more reliable in Firefox. It didn't remove the links to Seattle Times when I tested it on this talk page. Another idea would be for it to remove distracting line breaks, like those at the Main Page. Graham87 15:39, 17 October 2008 (UTC)
Thanks! The script doesn't remove external links such as the Seattle Times links above, because I thought casual readers might want to follow those. If you try the script again on this talk page, you'll see that your and my internal links to Seattle Times in this section are removed, but the external links above are not. The script also keeps other potentially useful links that don't interrupt the reading too much, such as the inline citation links, the navigational links at the left, and the buttons for editing each section. I'd appreciate your suggestions and help in deciding which links to keep and which to eliminate.
I'm not sure which line breaks you're referring to on the Main Page, but I'll try to improve the script's performance there. The Main Page and other such portals seem qualitatively different from a typical article, don't they? Instead of having a linear flow, the Main Page is more like a six-ring circus, with major unrelated sections such as "In the news" and "Today's Featured Article". I'm not sure whether the HTML code provides enough clues about the portal's structure and I can imagine that such portals would be significantly harder to navigate. Proteins (talk) 09:47, 18 October 2008 (UTC)
- Ah I didn't notice that the Seattle Times links above were external links. Keeping them in is fair enough then. What a useful internal link is depends on the reader - one user might need a definition of a particular word while another wouldn't. I think keeping links within lists would be useful, as links are an important part of lists. An example would be a list like Lists of French people. Removing date links and red links would be a good idea, because date links are distracting and red links are unlikely to be useful to beginners who just want to browse articles. Graham87 11:48, 18 October 2008 (UTC)
Thank you, Graham, I updated the script as you suggested. Now the script keeps list-links (except when those are references or footnotes) but eliminates redlinks throughout. Removing date links seem more difficult, so I haven't done that yet; but most of them were in the References section, where they're now deleted. I kept the ISBN links in the References, though, since they seemed equivalent to external links. Someday I'll figure out how to customize the script so that the user can specify which links they'd like to eliminate. I haven't had the chance to test the new script much, but it seems to work on a few articles such as List of French people, William Shakespeare, Sloop and a few others. Please let me know of any bugs you come across, and also fill me in on what you'd like for the Main Page. Thanks, Proteins (talk) 14:36, 18 October 2008 (UTC)
- Checking out the Main Page more closely, it seems to be a special case. The line breaks I was talking about are in the lines "Welcome to Wikipedia,\ the free encyclopedia that anyone can edit.\ 2,587,508 articles in English". I've put backslashes where line breaks are read out with JAWS. There is also text that should be linked there, like the "overview" and "featured content" links, and the "more" link after today's featured article. I'm wondering how useful the strip links gadget would be on the Main Page, since the entire purpose of the page is as a springboard for going to articles in Wikipedia. Maybe it could strip out all links except those in bold or something. The Main Page actually reads quite well with a screen reader because of the headings. Graham87 15:06, 18 October 2008 (UTC)
I think I can keep links on the Main Page enclosed in bold type, but discard the others. The Main Page has special tag id's, often starting with "mp-", so it's easy to recognize. It may take me a while to find the right logic, though. I can definitely eliminate the two line breaks, you mention as well. Is there anything else you'd like for improving the Main Page? Personally, I'm having trouble navigating between the major sections of the Main Page using the keyboard; how do you do it? Proteins (talk) 15:29, 18 October 2008 (UTC)
OK, I think it works, but I'll have to eliminate the line breaks later. Enjoy! Proteins (talk) 15:40, 18 October 2008 (UTC)
- It's discarding all the links in bold type instead of keeping them. To navigate the Main Page with JAWS, I use the "h" key to go to the next heading. Graham87 16:15, 18 October 2008 (UTC)
That's interesting: the script works fine in Fire Fox 3 on Vista (at least for me), but fails in Internet Explorer for the Main Page and Lists of French people. I'll have to do more research on how the pages are rendered in IE; perhaps a different Document Model is being used? Proteins (talk) 17:38, 18 October 2008 (UTC)
PS. Just to clarify, bold-faced links are given special preference only when they're on the Main Page. Bold-faced links on other pages are stripped as usual. Proteins (talk) 17:47, 18 October 2008 (UTC)
I tested the script on Fire Fox 3, Opera, Safari, and Google Chrome, and it worked correctly. The lone holdout was Internet Explorer 7. Most of the IE7 bugs were resolved by refreshing the cache memory; the browser was using an old version of my script instead of downloading the new version. However, something was still unacceptable about my code for updating images, as I observed at Bacteria and William Shakespeare. So I eliminated that code for now, until I can fix it, and the script ran fine. Proteins (talk) 03:09, 19 October 2008 (UTC)
- Yes, it works well on the Main Page on IE7 now - it sounds much more pleasant for general reading. The only links I'd add now are the links labelled "Overview · Editing · Questions · Help", and so on, and the links after "recently featured" in the featured article and featured picture sections. Graham87, 05:00, 19 October 2008 (UTC)
Thanks, I think I might've corrected those things, although the linebreaks are still a problem. Please let me know if you find any other bugs or shortcomings of the script.
I noticed that Fire Vox skips the interwiki links on the Main Page that do not render in Roman letters, as though they weren't there. In one way, that makes sense, since Fire Vox would fail if you follow that link. On the other hand, it seems strange that the screen reader wouldn't note that Wikipedia has Arabic, Chinese and Russian versions. For fun, I'm drafting a little script to translate the interwiki links into English. Proteins (talk) 13:55, 19 October 2008 (UTC)
- I would also like the links labelled "Contents · Categories · Featured content · A–Z index" on the Main Page to be kept as well. I'll let you know if I find any other problems. Graham87 14:30, 19 October 2008 (UTC)
Believe it or not, I did that before I wrote. Once again, the script works perfectly on every browser except IE7. Please try refreshing your cache, but I suspect that the problem is with IE itself. I'll have to look into it further. I may have to write separate scripts for people who'd like to use Internet Explorer, or include an internal check for IE. Proteins (talk) 15:13, 19 October 2008 (UTC)
- I've refreshed my cache and it works fine here on IE7 now. Graham87 15:44, 19 October 2008 (UTC)
That's a relief! Perhaps my problem with IE7 is also cache-related, although I tried refreshing it once. In case you're interested, I finished a rough draft of User:Proteins/translateinterwikicodes.js. It translates the interwiki links in the lefthand column, but not yet those at the bottom of the Main Page. Thanks for your help in improving the scripts, Proteins (talk) 16:36, 19 October 2008 (UTC)
- That's nifty - it would be useful for sighted people as well. It doesn't translate the links containing Template:Link FA in the article India properly under either IE 7 or Firefox 2. It would also have to deal with the redirects to that template as well. Graham87 02:13, 20 October 2008 (UTC)
Thanks, Graham, I think I've fixed the FA-link problem. I also suppressed the acknowledgment messages for translating each interwiki code, since I imagined that people wouldn't want to hear them. I posted the script on my user page, but I'll keep checking whether the script works well in different browsers and on different Wikimedia projects. Thanks again for your quick help! If you have any other wishes for scripts, whether for accessibility or otherwise, please let me know. I have a few ideas of my own as well... Proteins (talk) 13:12, 20 October 2008 (UTC)
- The script sounds good now. Thanks for your work in creating and improving the scripts. I'll let you know if I think of any other ideas. Graham87 14:27, 20 October 2008 (UTC)
Hi, would you mind trying the striplinks script again on Internet Explorer? I was frustrated that the image code wasn't working there, so I've tried to fix it. It seems to work on my version of IE7, but that's only one datum. I wouldn't want to recommend the script if it were still broken, especially since IE is such a popular browser.
In the new version of this script, you'll probably hear the image caption repeated twice, but the first reading should be prefaced by the word "Image" and its number on the page. I also flagged some images that were invisible before, since they had no ALT text and no caption, such as those in navigation boxes; I hope that was the right thing to do.
As an additional feature, I was thinking of adding the total number of images to the ALT text, as in "Image 3 of 14:" I thought people might like knowing roughly where they are on the page. I could do the same with section numbering, for example, "Section 4 of 9: Translations of Shakespeare". Alternatively, I could give an estimate of how long it will take to read the remainder of the article, as in "You've read 33% of the article, with an estimated 45 minutes left to go" or give a quick link back up to the table of contents. In a really long Featured Article, people might want to skip sections that don't interest them. Lastly, I was thinking of making a hyperlinked List of Figures, a List of Tables and perhaps a List of Abbreviations analogous to and next to the Table of Contents, similar to what's found in academic textbooks and papers. Do any of those ideas seem helpful? I know that you can navigate easily using keystrokes in JAWS, so they might be superfluous. Proteins (talk) 21:08, 20 October 2008 (UTC)
- Yes the image captions read fine in my test case, India under IE 7. I think something like "image 4 of 14" would be useful, as images are a good indication of a reader's progress through an article. I personally wouldn't need the lists near the table of contents - I can use "g" to move to another graphic, or "t" to move to another table. However they could be collapsable lists like "show a list of tables" or "show a list of headings". Another idea for the script would be either to move the edit links out of the heading titles, or remove them altogether, since people who use the script will be primarily interested in reading articles. I hear something like "Etymology edit" when I move between each heading: I'd prefer to just hear "Etymology". Graham87 03:43, 21 October 2008 (UTC)
Hi Graham, I made the changes you suggested, the "image 4 of 14" and removing the edit-section links. Your idea of making the Figure, etc. tables collapsible is excellent, too, but since such tables aren't urgently needed, I think I'll hold off on adding that feature until I finish some other scripts. I'll write to the few other editors that I've met, and see whether they have any suggestions for this script.
I'm developing another script User:Proteins/articlestructure.js to analyze the structure of articles, such as how much prose is devoted to each section. It's not really accessibility-related, but you might find it useful or it might give you ideas for other scripts that could help Wikipedians to write articles. I'm giving a seminar for some scientists in December with Tim Vickers and I'm beginning to develop tools that might help the newbie professors to "hit the ground running". Proteins (talk) 16:47, 21 October 2008 (UTC)
Visualizing x-y plots
Hi Graham, I made a subsection, since that section was getting long, don't you think? Besides, I have a new question.
What's customary for making two-dimensional x-y plots accessible to visually impaired readers? I was thinking you could represent such a plot acoustically by varying frequency (y) against time (x). For example, a straight line could be represented by a slow chirp, gradually increasing frequency with time. Some nice benefits of this approach is that you can represent multiple signals at once, and if they get close, you can tell how close they are from their beat frequencies. Other sonic alternatives — such as varying volume (y) against time (x), or volume (y) against frequency (x) — seemed less ideal, since people generally lose hearing as they age and might mishear a volume-based curve, especially if frequency represented the x-axis. I'm interested in the problem because I'd like to make the numerical results of future scripts accessible to as many editors as possible. It seems like an old problem, one that smart people have surely considered and found solutions for; I'd hate to re-invent the wheel or go against custom. If you could fill me in, whenever you get a chance, that'd be great. Thanks, Proteins (talk) 20:21, 21 October 2008 (UTC)
- I studied advanced mathematics in high school so I had to deal with this problem. I used GTCalc, a talking graphic calculator made in Australia, to visualise graphics. It had a feature that allowed one to visualise a graph. It could only handle one graph at a time. You would type in the domain of values you wanted to hear (x and y minima and maxima), and it would make a sonic representation of the graph by varying the frequency based on the y-axis only. There was also a feature to trace the graph. The Audio Graphing Calculator converts graphs into audio in a similar way, but it plays white noise when the y-axis is below 0. GTCalc might still be available through Vision Australia, and I still have a copy of it. A thirty-day evaluation version of the Audio Graphic Calculator is also available. Seeing with Sound seems to be an even better program that can, among other things, convert graphs to audio, but the site has over-aggressive anti-spam protection and for some reason I'm banned from it. Graham87 04:52, 22 October 2008 (UTC)
- The Seeing with Sound program, or vOICe as it is properly known, is very nifty indeed. It converts images into sound using the stereo position to indicate the position you are hearing, the pitch to indicate the nddepth, and the volume to indicate brightness. It comes with an in-built audio graphing calculator, which comes with many more options than the commercial alternatives. It can also convert images from the web into sound. The spam protection on the vOICe site is not over-aggressive: there are invisible links which, if clicked on, ban your IP address from the site, and I happened to activate one of those links with JAWS. Graham87 14:51, 22 October 2008 (UTC)
- While I remember, the link that explains the graphing calculator part of vOICe is here, which also contains links to other good sites about mathematics for the blind. Graham87 16:38, 22 October 2008 (UTC)
- The Seeing with Sound program, or vOICe as it is properly known, is very nifty indeed. It converts images into sound using the stereo position to indicate the position you are hearing, the pitch to indicate the nddepth, and the volume to indicate brightness. It comes with an in-built audio graphing calculator, which comes with many more options than the commercial alternatives. It can also convert images from the web into sound. The spam protection on the vOICe site is not over-aggressive: there are invisible links which, if clicked on, ban your IP address from the site, and I happened to activate one of those links with JAWS. Graham87 14:51, 22 October 2008 (UTC)
That's great that you know so much about the subject! I looked over the three plotting programs you mentioned in your first reply, and I'm also impressed most by Seeing with Sound. Their links to other sites, such as the tactile force feedback, were fascinating as well. It's going to take a while for me to become familiar with all these various tools. But perhaps the take-home message for me is that this is a solved problem already?
I imagine that if you wrote to the Seeing with Sound people, they'd re-instate your browsing privileges. It sounds like an innocent mistake. If you wanted me to intercede for you, I'd be happy to do that; being a professor has at least a few advantages.
As I wrote on my talk page, I'm working on your list-merger problem. It's fixed except when you have multiply-indented text, as often happens on Talk pages; I'm still thinking about how to solve that problem.
The way that Seeing with Sound uses stereo hearing reminded me of my old friend Gill Pratt when we were at MIT together twenty years ago. His Masters thesis in electrical engineering was a headset system that used stereo sound to tell blind people which way was North; we had a lot of fun trying it out for him. Nice memories, Proteins (talk) 17:41, 22 October 2008 (UTC)
- I got unbanned last night, which is how I was able to try out the program. I should have been more clear about that in my previous messages. Gill's thesis reminds me of the C2 Talking Compass. Graham87 07:10, 23 October 2008 (UTC)
Working script for outdenting discussions
Just a heads-up that I got the initial bugs out of the outdenting script, User:Proteins/outdent.js. Would you test it out and look for any remaining bugs? That'd be great. I made the access key "o", so if you're using Firefox, ALT-SHIFT-O should outdent everything that should be outdented. I don't think that conflicts with another access key, but let me know if it does. Note that the older script User:Proteins/unindent.js should NOT be used any more, because of its bad bugs. Thanks, Proteins (talk) 23:25, 24 October 2008 (UTC)
- The access key "O" is the key for "Log in / create account", so there is a conflict in this case, but it doesn't matter because if a person is accidentally logged out and tries to use the indentation script, logging in is exactly what they'll want to do. However the access key doesn't work on IE 7 but works on Firefox. It works fine on this long boring discussion which goes to indent level 14. However for discussions like Wikipedia:Articles for deletion/Steve Pariso, it should remove the bullet points and/or the line breaks so it sounds much better with JAWS. Graham87 03:48, 25 October 2008 (UTC)
The problem is that HTML tags such as <ul> start a new line automatically, as you can see at the bottom of this sandbox. The only solution is to put the "(Indent n)" text within the list item, which I'll try to do now... Proteins (talk) 18:34, 27 October 2008 (UTC)
...OK, the script seems to be working; I tested it on my sandbox tests, the Steve Pariso AfD, the jbmurray RfA, and the talk page of FAC. But it might have some stealthy bugs; please let me know if you uncover anything amiss. Thanks, Proteins (talk) 20:21, 27 October 2008 (UTC)
- It still makes JAWS say "list of 1 items" and so on before each indent in the AFD in both Firefox and IE (and I've refreshed Monobook.js on both browsers). Looking at the source code more carefully, it seems the easiest thing to do would be to put the bullet point before any indents. But that sounds like what you said above, so I'm beginning to wonder whether I'm having a caching problem. Graham87 02:05, 28 October 2008 (UTC)
You're right, that's what the new version script tries to do. The script keeps the bullet point, which marks the list of one item. Some editors seem to use that bullet point to indicate that a new editor has begun speaking; although it's usually redundant, I was loath to delete that style-mark. Instead, the new version of the script changes where it places the "(Indent x)" text and removes the linebreak that had preceded the bullet point; now, it places the indent text just inside the list item, so that it comes after the bullet point with no line break.
I tested the script on the Steve Pariso AfD on Firefox 3, Google Chrome, Opera and Safari, and it seemed to work at least on my screen. The two bullet-pointed lines, namely Ten Pound Hammer's comment "A who what?" and your reply, should be bullet-pointed and unindented like all the other comments on that page. If that's not so, perhaps try refreshing your cache with Cntrl-F5, which I've found works on both IE and Firefox 3. Also, please make sure that you're using User:Proteins/outdent.js and not the obsolete version User:Proteins/unindent.js.
Removing the list and bullet point altogether is possible in principle but would be more difficult. I'm afraid it would be difficult to write a script that would deal appropriately with all the pathologies that users would throw at it.
One thing I haven't done is add a third-pass loop to delete the now-empty discursive lists that were used to make the indentations. They're invisible to me, that is, they aren't rendered by the browser; but a sufficiently clever screen reader might note their presence in the Document Model tree — or perhaps that should be a too-clever-by-half screen reader. I'm thinking of deleting them, but it's always a little dangerous to be deleting elements in the document, so I'm working on the rest of the script first. Proteins (talk) 11:21, 28 October 2008 (UTC)
- Aha, it's the empty discursive lists that I'm hearing with JAWS. I hear them on both Firefox and IE. They sound slightly better under the outdent script than they do when the page is loaded normally. There are many weird and wonderful indenting styles out there, from bullet points to ordinary spaces, so I understand your reluctance to deal with some of the more exotic ones. Graham87 13:23, 28 October 2008 (UTC)
Ok, that's helpful to know! I think I've fixed the script. The deletion loop is slightly more aggressive than it should be, but it shouldn't be a problem for most articles. I even know how to fix that problem, but today's my birthday and my wife and I are about to make a nice dinner, so I'll get to it tomorrow. I tested the script on the sample articles mentioned above, and the new version seems to work fine. Enjoy! but let me know any other problems... Proteins (talk) 00:31, 29 October 2008 (UTC)
- Hmmm, I'm still getting discursive lists in the above-mentioned AFD debate, in both Firefox and IE 7. I've refreshed Monobook.js in both browsers and it's still not working properly. Also, when I pressed enter on the "outdent" link to activate the script, the alert didn't come up in IE as it should. I'm not sure what's going on. Oh BTW happy birthday. :-) Graham87 05:19, 29 October 2008 (UTC)
It ain't over 'til it's over; code isn't code until it's working code. I hadn't tested the script on Internet Explorer, which seems to be much stricter about valid JavaScript; the browser seems to throw an error if you take the property of a null DOM object. To make the script work, I added exhaustive checks on the NULL status of every object, which is good programming discipline. I always do that in more basic languages, but I'd mistakenly thought that JavaScript was smart enough to handle that automatically.
I tested the script on the Steve Pariso AfD in five browsers: Firefox 3, IE 7, Opera, Safari and Google Chrome. In all the browsers except Opera, I can check the DOM tree after running the outdent script; the DL elements have been deleted. I added diagnostic messages to confirm that as well. I tried the sandbox tests, the jbmurray RfA, and the talk page of FAC on IE7, Chrome and Firefox 3, and they seemed to work as well. Try it again? Thanks, Proteins (talk) 16:19, 29 October 2008 (UTC)
- As I've just figured out, the discursive lists JAWS is reading aren't definition lists at all. They are unordered lists. Here is what JAWS says when I run the outdent script on Wikipedia:Articles for deletion/Steve Pariso under both FireFox and IE, with caches refreshed:
list of 1 items •Delete There is no assertation of notability. In fact, the whole things reads like a CV. -- Malcolmxl5 08:20, 31 July 2007 (UTC) list end
list of 1 items •(Indent 1) A who what? Ten Pound Hammer • (Broken clamshells •Otter chirps •Review?) 12:13, 31 July 2007 (UTC) list end
list of 1 items •(Indent 2) CV=curriculum vitae, known in North American English as a Résumé. Graham 87 12:33, 31 July 2007 (UTC) list end
list of 5 items <The rest of the AfD ...
- The same thing occurs on your sandbox. I know I've had caching problems, but I've cleared out my temporary files area to make sure that no old versions are lurking in my computer.
- How do I get at the DOM tree, so I can hear what JAWS is using to present the page? Thanks, Graham87 00:54, 30 October 2008 (UTC)
First the good news. I've begun writing a tutorial on scripts, User:Proteins/Writing_scripts_for_Wikipedia and the first section I've written is the one you asked for, how to see the DOM tree on different browsers.
The bad news is that what you're hearing is exactly what you should be hearing, according to my initial design. Here's how my script works. In the first pass, the script identifies the DD elements in discursive lists (also called definition lists) that are not underneath or adjacent to a DT element; it keeps track of the indentation level and labels and colors everything according to that indent level. In the second pass, it places everything inside those DD element into new DIV elements, hoists those DIV elements out of their discursive lists, placing them before them. In the third pass, it uncreates the now-empty discursive lists. Therefore, if the editor used an unordered list of one item to make a little bullet point, then you'll hear that because it got packaged into its DIV element along with everything else.
There are several solutions. The simplest is to add to the script a fourth-pass loop over the new DIV elements (which I've labeled for just such a purpose), and then eliminate whatever elements we wish to eliminate, such as unordered lists, without destroying the essential content within them. That will remove the bullet point that the user added for style, but we could replace it with a nearly equivalent marker. Alternatively, I could try to write some logic into the script to see whether such buried unordered lists could be integrated with a surrounding unordered list. Lastly, we could try to educate people that they don't need that little bullet point to indicate that a new person is talking, but that seems more difficult. Proteins (talk) 13:12, 30 October 2008 (UTC)
- I was thinking that the little unordered lists could become nested, so basically turning the wiki-markup ":*" or "*:" into "**", and add more nesting for each additional colon. I'll check out the IE toolbar tomorrow morning my time. Graham87 14:40, 30 October 2008 (UTC)
I'm surprised that "**" is read differently than what's produced by my script. Doesn't JAWS also say something like "list of one item" to indicate the sublist of the "**" element? Since I don't have JAWS, I'm flying blind, if you'll forgive the well-meant joke. ;)
I'm game to keep working on the script if you are. It seems as though we're close to a good solution, if we can only communicate to each other what we're striving for. I'd thought that the definition lists themselves were the problem, that JAWS would read a triply-indented bullet-pointed reply "I agree." preceded by a linespace as something like
definition list of one item • definition list of one item • definition list of one item • unordered list of one item • I agree. • end of unordered list • end of definition list • end of definition list • end of definition list
My initial goal was to convert this into the much shorter text
unordered list of one item • (Indent 3) I agree. • end of unordered list
which the script does now. If the unordered list could be eliminated, either by more sophisticated programming or by educating editors not to add that redundant element, the minimal version would result
(Indent 3) I agree.
That's my understanding of our goal. Did I misunderstand something? Perhaps JAWS is smart enough not to read out all those "definition list of one items" when text is indented? If you could clarify the goal for me, that would help in writing a more useful script. JavaScript confers nearly perfect control over the elements of a webpage, so nearly any desired modification of lists and indentations is possible with sufficiently sophisticated coding.
I made a a new sandbox to experiment with lists and indentations. We might find it helpful in defining the desired behavior of the script. Proteins (talk) 16:44, 30 October 2008 (UTC)
- Yes, JAWS says something like "list of 1 items nesting level 1" when coming in to a new unordered list. It does not make a distinction between ordered and unordered lists. You can actually download a free demo of JAWS to play with these things at the Freedom Scientific website.
- The thing is, when reading an AFD vote, I ideally want a continuous unordered
list. I want to be able to move to each vote by pressing "I" to move to the next list item. When hearing "list of x items" with JAWS, I also want an accurate count of the number of votes, not including the indented discussions. That's why I was thinking of using nested lists, because I thought inserting a line break always ended a list. However that doesn't seem to be the case, as proven by my sandbox at User:Graham87/sandbox9, which represents the ideal way I would like to hear discussions using both indents and bullet points. Both my tests sound exactly the same with JAWS: the first one uses lists created with "*" while the second one uses HTML elements to create the list. Graham87 01:26, 31 October 2008 (UTC)
OK, I think I get it now. I downloaded the demo version of JAWS and learned enough to figure out some things that I hadn't realized. First, I had mistakenly believed that JAWS was reading the indentations aloud as definition lists, as I wrote above, but that's not true. For example, the indented sentences in this sandbox all read as though they were unindented, whereas I has imagined that JAWS was reading them like
definition list of one item • This sentence is indented once. • end of definition list
So I was solving a problem that didn't need to be solved. On the other hand, you might appreciate knowing that a text is indented, to flag when a new comment is being made, so perhaps it wasn't a total loss. Speaking for myself, I like being able to see the comments in different colors, and not wasting all that screen space with indenting. As an aside, is there a way in screen readers to flag text so that it's read in different voices? That might be the equivalent of seeing text in different colors.
The two examples you give in Sandbox9 are helpful, too, although you might be amused to know that the DOM tree representations of both are identical, except for the extra BR tag at the end of the second example.
Am I correct in assuming that you're OK with eliminating all indented unordered lists? That would leave you with unindented unordered lists, which are the ones you care about, right? I'll make sure to merge them so that you can count the votes. As another alternative, I could write you a simpler script that would just count and read off the list items that begin Keep, Delete or some other bold text. I have to go home in an hour or so to greet the children for Halloween, but maybe I'll try to write the latter script before then. Proteins (talk) 19:48, 31 October 2008 (UTC)
- Yes, elimination of indented unordered lists is what I want. Sometimes JAWS does read the indents as "definition list of 1 item nesting level 1, nesting level 2 ..." which can get very annoying. I don't know of a way to predict when it will try to read out indents in this way. The Speech and Sounds Manager in JAWS lets you customise a different voice or a particular sound for headings, indents, colours, fonts, or anything you care to customise. However I don't like voice changes so I don't use that feature. In fact my JAWS configuration is quite eccentric, and has been fairly strange ever since I started using the program in 1999. Graham87 06:02, 1 November 2008 (UTC)
AfD summarizing script, possible FAC application
Hi Graham, I wrote a new script, User:Proteins/summarizeAfD.js, that summarizes the AfD !vote counts and who voted what way. The script ignores indented comments. You might find it useful in your work, at least as a quick overview since I understand that AfD's are not supposed to be votes. The script access key is "a", I hope that's OK. Let me know if you like the new script and whether I can improve it. I might make something similar for FAC's, although I know they're not supposed to be votes, either. I'll get back to the outdenting script on Monday. Proteins (talk) 04:15, 1 November 2008 (UTC)
- I like it. I've tried it on this trainwreck of an MFD (for deletion of Wikipedia namespace and user pages, which have the same format as AfD's), and the script seems to evaluate it as I remember it. However, when it finds a signature that it doesn't recognise, I'd like it to tell me what that signature is so I don't have to go waist-deep into the AfD to find it. If it doesn't do it already, it should count user talk pages the same as user pages in sigs, because some people sign with a link to their user talk page only. Graham87 06:02, 1 November 2008 (UTC)
- Also, on access keys, alt-A gets me to the favorites menu with Internet Explorer, but it doesn't really matter right now because none of your access keys work in Internet Explorer 7. Graham87 06:40, 1 November 2008 (UTC)
Hey Graham, I'm glad you like the script. I do determine the User talk page, if one is provided, and use it as a substitute for the User name if the latter is missing. In the new version, I added two new categories of votes (refactor and transwiki); the script also gives the list item in full when an error is encountered. Some of the errors on the Esperanza MfD seem to have been valid !votes, so I'll have to go back and find out why my script didn't flag them as such; but you can tell what they are from the error messages. Proteins (talk) 15:25, 1 November 2008 (UTC)
New script for expanding Wikipedia's acronyms
Hi Graham, this isn't really an accessibility issue, but can I ask your opinion on a new script? I've noticed that a lot of experienced Wikipedians throw around acronyms such as WP:OR or WP:V without explaining them for the newbies. I really noticed that a lot at WP:AFD while I was checking my previous script. On the one hand, you'd like to allow the WP experts their efficient abbreviations, but still make those acronyms accessible to others less experienced.
So I wrote a draft script, User:Proteins/expandWPacronyms.js, that expands hyperlinked acronyms that start with "WP:" in place in the article. Experts don't need to click on the acronym tab, so they see the usual page; but by clicking, newbies can see a different version in which the abbreviations are explained in parentheses after the acronym. The access code is "x", for what it's worth. After you mentioned it, I discovered that none of my access codes work in my version of IE7, either. It's not clear how to solve that problem.
The script uses a dictionary-lookup approach similar to the one I used for the script translating interwiki links. I've started with a draft dictionary of 25 acronyms, the Five Pillars and some common policies and guidelines, but I intend to add many more. If you get a chance to try the new script out and if you have any suggestions, I'd appreciate it. Thanks! Proteins (talk) 01:05, 3 November 2008 (UTC)
- Hi Proteins, I find the use of abbreviations annoying as well, and I like the essay about it: Wikipedia:WTF? OMG! TMD TLA. ARG!. Maybe it can follow the redirects and use that as the title, Good places to test the script are Wikipedia:Administrators' noticeboard and Wikipedia:Administrators' noticeboard/Incidents. Graham87 02:13, 3 November 2008 (UTC)
I'm not personally annoyed; it's natural for people to find abbreviations for terms they use frequently. For instance, you see three-letter codes being used for amino acids by biochemists and for saints by the painters of old Greek icons. But it'd be nice to find a way to include the newbies without inconveniencing the dinosaurs. Your funny essay make the point well that these abbreviations shouldn't become a shibboleth; thanks for pointing me to it! A JavaScript script seems well-suited because different people can view the same article in different ways.
I tried the script on the Administrators Noticeboard, and I discovered that it works OK, but that I need to add dozens more abbreviations to my dictionary. The link to WP:WP on the essay will be useful for that. The script also has to allow for punctuation within the double brackets, and other anomalies. In a later version of the script, I'll replace abbreviations that are not hyperlinked. Proteins (talk) 21:00, 3 November 2008 (UTC)
An easier way to figure out what's been changed in a diff
Sometimes I would like to view just the text that has changed in a diff, with none of the surrounding text. At the moment, to check diffs thoroughly, I go into the HTML source and search for "diffchange". It would be nice if I could do this automatically. Graham87 02:13, 3 November 2008 (UTC)
- OK, let me know what you think of User:Proteins/quickdiffs.js. It summarizes how many additions, deletions and text replacements were made in the diff, and goes on to specify those in detail. The latter corresponds to your search over "diffchange" SPAN elements in the HTML source. The access key for the script is "b", in case you're using Firefox.
- One thing I noticed: there's a bug in the MediaWiki software for calculating diff's. It does not find the optimal match of text between the two versions. For example, in this diff, the paragraph near the end that begins "Further you stated" is not matched in the old and new versions. The algorithm prefers to match that paragraph in the old version with an entirely new paragraph in the new version; that's why there are thirty-some additions and deletions. I tried to make a work-around, but it didn't work on my first try.
- In a later version, I'll more information to the initial summary window, such as the times, editors and edit summaries of the two versions being compared. That'll be relatively easy, but I'm a little pressed for time today. Proteins (talk) 21:16, 3 November 2008 (UTC)
- It works well with the diffs I've tried on my watchlist. There are grammar issues - "there were one replacements" and the like. Sometimes the difference engine doesn't work well at all, especially where whitespace is concerned, and sometimes when text is moved around. I'll let you know if any other issues come up. Graham87 23:41, 3 November 2008 (UTC)
- On this diff, it should just say that nothing has been changed rather than spitting out an error message. However it's pretty easy to figure that out by examining both the diff window and the edit summaries, so that's a minor quibble. Graham87 23:47, 3 November 2008 (UTC)
- I think I've fixed the grammar problems and the script now checks whether the two versions are identical. It never occurred to me that a diff could yield no difference, so thanks for pointing that out. I also added code that parses the headers of the older and newer versions, to find data such as the revision date, its author, and the edit summary. Should I add that kind of data to the summary message in the first alert window, or would that be superfluous? Briefer might be better. Other suggestions for the function and presentation are always welcome, of course. Proteins (talk) 14:55, 4 November 2008 (UTC)
The contributor info is superfluous, as it's already clearly displayed in the diff window. However, the diff for this edit could be displayed better: perhaps the script is getting confused because of the use of colons? The edit summary is self-explanatory though. Graham87 01:20, 5 November 2008 (UTC)
- Hi Graham, thanks for finding that bug in the script. I'm not sure why it was mis-categorizing deletions as text replacements, but the bug may have been related to my attempts to fix the shortcomings of MediaWiki's difference algorithm. In any case, I think I've fixed that bug. The other issue, the splitting of the interwiki replacements into two parts (such as "fr" and "pontage aorto-coronarien"), happens because the colon matches between the old and new interwikis. I could fix it for this difference, but it probably would be difficult to find a solution for all articles. Proteins (talk) 04:39, 5 November 2008 (UTC)
Hey Proteins, the diff above sounds much better now. I didn't think about the colons in interwiki links but that explanation makes sense. Most people/robots adding interwiki links do so with an informative edit summary, so getting diffs to work for them is not a high priority. Graham87 05:37, 5 November 2008 (UTC)