Talk:Centum and satem languages/Archive 1
| This is an archive of past discussions. Do not edit the contents of this page. If you wish to start a new discussion or revive an old one, please do so on the current talk page. |
| Archive 1 |
Thracian
The Thracian corpus has preserved a number of Satem examples, but its classification as Satem is still being discussed. Sorin Olteanu states that Thracian was a Centum language till a later period when it became Satemized under Balto-Slavic influence. We have no idea what the Thracian word for hundred was, and some Thracian words don't show the sibilant. This article notes that it is only "perhaps" Satem, not definitely, so no problem. Alexander 007 07:07, 20 May 2005 (UTC)
- I wouldn't have thought there was enough information on Phrygian and Thracian to say definitively one way or another. But there is evidence that some Anatolian languages were satem even though Hittite was centum, and Luwian seems to have been both: it kept *k and *kw distinct but made a sibilant (spelled z, probably [ts]) out of *ḱ. --Angr/comhrá 07:15, 20 May 2005 (UTC)
- Because of unsufficient data, it is hard to say anything on the above mentioned languages. It is however worth to mention that in each satəm language there are words with velars in the place of PIE palatals. For instance, the original palatals, as a rule, give velars in Slavic when the root contains an original "s". Just compare Lithuanian žąsis and Old Church Slavic gǫsь 'goose' (< PIE *gʹhans-i-).
- I have not heard about satəm words in Luwian but I have heard on such words in Lycian. However, notice that Lycian is known from inscriptions form V-IV BC, i.e. very young when compared with Hittite. Such single Lycian words as snta "100", esbe "horse" or sijeni "it is lying / recumbent" may be borrowings from a Satəm language close related to Phrygian (if it really was Satəm) or Proto-Armenian. Some scholars, like V. Georgyev, believe that some late Anatolian languages had mixed character and had two components: an older one, close related to Hittite, and a newer one, Satəm. Three or four satəm words are known from Hittite itself. The most reliable and most widespread opinion is that they are borrowings from early Indoiranian spoken by people who inhabited Mitanni once.
- --Grzegorj 20:56, 4 August 2005 (UTC)
Dacian
I added Dacian, because it was at least semi-Satem. Alexander 007 07:22, 18 July 2005 (UTC)
It's a shorthand term I used to describe a language that may have had Satem reflexes only very irregularly (Phrygian) or as a later development. The evidence for Dacian being Satem rests on examples such as the ones I've listed here:Talk:Dacian language. Alexander 007
- All right but please do not term (s)kazat(sya) Common Slavic! It is Russian, not Common Slavic ((s)kazat'(sya) in transliteration). The Common Slavic form was kazati (attested in Old Church Slavic) and sъkazati, with the meaning "show something with gesture", not just "show" (see Vasmer, Russisches Etymologisches Wörterbuch). The Old Church Slavic and Common Slavic medium voice was kazati sę and sъkazati sę. The PIE form with *kw- is not very likely, see Sanskrit śāsati, śāsti 'he/she shows with gesture', but also kāśatē 'it shows up' < PIE *k'ōs-, *kōk'- or *kōg'- (as far I know, the reconstruction of initial *kw- is based only on Greek tekmar 'sign' < *kwek-).
- --Grzegorj 22:13, 4 August 2005 (UTC)
- Yes, the form is Russian, not Common Slavic. The etymology from *kwek- (or *kweg-) is based on my AHD from 1969, and they may have been wrong, but I think Olteanu in his current LTDM site still gives an initial kw- (Read this, it may be of interest). Alexander 007 22:20, 4 August 2005 (UTC)
There is no evidence that Thracian and Dacian were separate languages. In fact, the ethnonym Thrax (Thrāix), Threēix is known as long time ago as in Homer's texts. Northern Thracians were known as Getai in classic Greeks' times. Other Getai / Getae were known from the Dnestr region (Tyragetae), from the Don mouth (Thussagetae) and from the northern shore of the Caspian Sea (Massagetae). So, they may have been an Iranian tribe which was Thracized. In the Roman times Dacians (Daci, Dakoi, Dakai, Dakes) show up for the first time and they are count within Getae (so, within Thracians).
The number of Daco-Thracian satəm words exceeds those which are centum. So, we have insufficient evidence to count them within Centum. The term "Semi-Satem" is ridiculous, because in Daco-Thracian there is a number of words with velars in the place of PIE palatals, for different reasons (not necessary borrowings from Centum languages), just like in other Satəm languages (no true Satem languages are known in fact). For example, Akmonia may be native, cf. Slavic kamy, gen. kamene 'stone' (a centum form in a Satem language), related to English hammer (originally "stone hammer"), Lithuanian akmuo and ašmuo 'stone' (centum and satem forms side by side!), Latvian asmens 'blade of knife', Greek akmōn 'anvil', Sanskrit aśmā 'stone, rock'.
Other Dacian and Thracian Satəm words are:
- Asamus, hydronymic, from *ak'm- 'stone', see above,
- briza 'a sort of corn', cf. Slavic rъžь, German Roggen 'rye' and the English word (< *(w)rug'h-)
- -diza, toponymic formant, from *deig'h- 'build in clay, in brick',
- Diuzenus = Greek Diogenes (*-g'-),
- -esp-, -ezb-, onomastic formant, from *ek'wos 'horse',
- Kozeilas, Kozaros, Kozinthēs, cf. Slavic koza 'goat', kozьlъ 'he-goat',
- Razea, Raizdos, Rēsos from *rēg'- 'to rule, to govern; king',
- Zantiala from *g'enH-t- 'clan, tribe; to give birth',
- Zoltes from *g'hol- 'golden, yellow'.
Other Centum words are:
- Anguron (now Iron Gate) from PIE *ang'- 'narrow' (however, see also Slavic ǫglъ 'corner' (Latin angulus)),
- argilos 'mouse' from *arg'- 'silvery, bright' (see Argessos above),
- Decebalus parallel with Sanskrit daśabala 'having the power of 10 men',
- Dekaineos also from *dek'm- 'ten',
- Peuci (Dacian), Peukē, Pecetum (Thracian) from *peuk'- 'to prick' (cf. Latin picus 'woodpecker', picea 'spruce')
- Trikornion, maybe of Celtic origin in fact, from *k'orn- 'horn' (however cf. Slavic *karvā 'cow', literary 'horned animal', also with k-, not with expected s-)
Most of them have parallels in other Satem languages.
--Grzegorj 23:34, 4 August 2005 (UTC)
- I agree, that's why I listed Dacian as Satem. Also, Romanian substratum words indicate satem-sound changes. One of the arguments against the Romanian substratum being "Illyrian" (as some may claim), is that Illyrian was most likely Centum (cf. Wilkes, et al.). So I have come to see the Satem nature of Daco-Thracian as a plus :) . "Semi-satem" is a concoction, and I would have used a better term, but forgot it on short notice. Alexander 007 23:42, 4 August 2005 (UTC)
- However, Vladimir Georgiev and Ivan Duridanov would not agree that "there is no evidence that Dacian and Thracian were separate languages". Viewing them as separate languages on the same Indo-European branch seems likely, unless further evidence indicates something else. Given the uncertainty, it is best to list Dacian and Thracian separate. For example, many of your satem examples above are specifically Thracian (briza, -diza, Rhesos, etc., though Rhesos may also be Dacian, but I'm not sure; interestingly, there is a Dacian name Regalianus). Alexander 007 23:50, 4 August 2005 (UTC)
Article needs some fixes
The Centum/Satem does not divided Indo-European into two dialects. The most accepted theory is that a sound change occurred very early in on area of the PIE and it spread to other areas. This explains why Indo-Iranian languages have complete Satem (the dialects in which the sound change probably occurred), Balto-Slavic has incomplete Satem, while the branches on the edge like Italic have no Satem changes.
For example, taken from Language History, Language Change, and Language Relationship by H. H. Hock and B. D. Joseph (1996, page 357), Father-in-law (PIE: *swek'uros): Sanskrit: s'vas'ura, Old C. Slavonic: svekuru, Latin: socer...Hundred (PIE: *k'm.tom): Sanskrit: s'atam, Old C. Slavonic: suto, Latin: centum...Notice that Old Church Slavonic has both /k/ and /s/ from PIE /*k'/.
Also, the sound change of the palatals to velars or sibilants may have just developed independently in the various branches of Indo-European, as this sound change occurs frequently across the worlds' languages. Any linguists want to work on this article?
- At the very least someone should point out that this is only one of many isoglosses that lies between the various IE accents. Mallory shows 24 in a diagram taken from Raimo Anttila, and for the most part the "K-S boundary" doesn't even fall along the densest bundles. — B.Bryant 09:43, 1 September 2005 (UTC)
I also can't vouch for the accuracy of the maps. Imperial78
I have edited the page which is more neutral in describing the sound change and at the end discussing the theories which the sound change is a part. Imperial78
Not so very mainstream
discussion continued from [1]
[the article at present has:]
- "The presence of three dorsal rows in the proto-language is still not universally accepted. The reconstructed "middle" row may also be an artifact of loaning between early daughter languages during the process of Satemization. For instance, Oswald Szemerényi (e.g., in his 1995 Introduction), while recognizing the usefulness of the distinction *kʷ, *k, *ḱ as symbolizing sound-correspondences does argue that the support for three phonologically distinct rows in PIE is insufficient and prefers a twofold notation of *kʷ, *k. Other scholars who assume two dorsal rows in PIE include Kuryłowicz (1935), Meillet (1937), Lehmann (1952), and Woodhouse (1998)."
"Still not universally accepted" sounds pretty NPOV, as if acceptance is some kind of obligation imposed by Wikipedia. Also, it has a taste of tampering with the definition of "mainstream". I would rather call "mainstream" the agnostic definition of Britannica. So please tell me, if not even the existence of three dorsal rows is universally accepted, then how will you make me believe a sound shift based on such a theory will be? Don't get me wrong, I don't mind you mentioning such a deduction if with the proper reference from your bibliography (just for avoiding the impression of OR). However, adhering to such a view implying an early and separate two-way division has consequences that are certainly not mainstream, like reusing the definition of centum to a subdivision that experienced such a centum sound change and excluding others. You call it agnostic, but I doubt many respected scholars will be interested in keeping an almost obsolete definition like "centum" alive like this. Satemization is much more interesting! (I wonder why no separate article about this subject exists). And please, at least improve the statement on Tocharian: it is not typical centum to combine all rows into a single velar row, this is a feature of Tocharian only. Rokus01 22:30, 28 February 2007 (UTC)
- the "still" isn't intended as temporal, but in the sense of "all the same". Feel free to rephrase.
- the three rows implicate the two mergers, and are indeed constructed to account for them. there is no leap of faith between assuming three rows and assuming the two mergers as you seem to imply. I'm not going to discuss this further. Consult any introduction to IE linguistics.
- "implying an early and separate two-way division has consequences that are certainly not mainstream, like reusing the definition of centum to a subdivision that experienced such a centum sound change and excluding others" — you still show no appreciation of the basic phonology of the isogloss. It is absolutely straightforward that both centum and satem underwent phonological change, hence it is absolutely straightforward that in principle there could be cases where neither applies. the question is, does there happen to be such a case or not.
- "satemization is more interesting" is a strange statement. You might say "satemization is more obvious" because of the phonetic changes (assibilation), but it is pointless to consider it in isolation. "interest" is subjective, but fwiiw, I would consider the centum change more interesting precisely because it is less obvious.
- "it is not typical centum to combine all rows into a single velar row" — yes? I would never suggest such a thing. I'll try to rephrase for clarity.
Haplogroups and Substratum Hypothesis for Satemization??
Does anybody think we should put some information about haplogroups? Also I am perplexed that the "R1a" homeland and the "satem" homeland are identical. What is the current scientific opinion on the above? Also what caused the satemization of PIE? Is satemization equivalent to palatalization? Can we say that modern Romance languages were also "satemized". I remember there was a study that said that the "satemization/palatalization" of vulgar Latin is related to a substrutum effect due to the conquered people of Western Europe by the Romans. Could the same have happened with the "satemization" in the so called R1a (Kurgan) "homeland" (dark red on the map)? If so who were those people, North-Caucasians? Thank you and I would appreciate your insights. Also any good sources addressing the above issues would be appreciated i.e. (books by experts in both genetics and linguistics) --Kupirijo 19:26, 11 February 2007 (UTC)
- This item deserves special attention. I would rather suggest to dedicate a separate article to satemization, covering linguistics, hypotheses, archeology and genetics. In the Netherlands such an article, listed in the languagebox, was well received. By the way, I don't know about theories on the cause of satemization, except grammaticalization: it just happened. Rokus01 06:55, 1 March 2007 (UTC)
- the "R1a homeland" is associated with the PIE homeland, not the "Satem" homeland. As it happens, Satemization was a "central" phenomenon, that is, it spread in ripples around the former PIE homeland, at a time when R1a had already been spread all over the place (think successive waves). Case in point: Norway has more R1a than Persia. Satemization is 3rd millennium, R1a (M17) is 10th millennium, that's an appreciable difference. Maybe there could be an argument based on microsatellites, I don't know, someone will have to look into that. dab (𒁳) 08:33, 1 March 2007 (UTC)
High occurrences of R1a1 among non-IE Lapps and anthropological evidence of pre-nordic races in Norway might point to a much more complicated history of R1a1 during the last 10.000 years. To assume the relation between R1a1 and PIE is one to one seems to me a little simplistic, or a romanticed view of National Geographic journalists. Somewhere in history IE males should have caught up (high concentrations of) this gene, probably during the expansion itself, otherwise Poland -having the highest rate- would definitely be the PIE homeland. There is no way of sticking staightforward to loose publications and accept OR, what we need here are facts, gathered from different disciplines. Then, let the reader decide. Rokus01 09:21, 1 March 2007 (UTC)
- yes, yes, that hardly needs pointing out. "R1a=IE" is simplistic nonsense. There does appear to be some intriguing correlation between R1a spread and IE expansion, but it is of course far from trivial; there is far too much time between M17 and PIE to make it straightforward. dab (𒁳) 09:47, 1 March 2007 (UTC)
Sound changes
Which variant from theese sound changes is correct for satemization:
1) k' > tš > š > s and g' > dž > ž > z
2) k' > ts > s and g' > dz > z
3) k' > h' > š > s and g' > gh' > ž > z
4) k' > h' > s' > s and g' > gh' > z' > z
5) some other
š is for Sanskrit and Lithuanian, and s is for Avestan and Balto-Slavic (except Lithuanian). h' is soft unvoiced h and gh' is soft voiced h, s' is soft s, z' is soft z'.
Attested changes are tš > š / dž > ž (Latvian), h' > š (Russian), ts > s (Spanish). Change š > s is doubtful, 'cause I don't know the real attestation of such change. Latvian also has attestation of change g' > ģ; ģ is pronounced as [d'] (~ eng. during).
For example, the numeral '8', originally *aki-tam, where aki - 'eye', Lith. 'akis'; tam - 'that'. So '8' - 'that with eyes', i.e. 'eyed', as we see, the number has two holes like eyes. ;) But how we can get astam (Old. Latv. astam-tas 'eight') from akitam? Roberts7 18:47, 18 March 2007 (UTC)
- Spanish does not have anything to do with satemization. The history of number 8 does not have any bearing with PIE. So what is the question? Rokus01 22:01, 18 March 2007 (UTC)
- Spanish was only example of attestation of ts > s change, nothing more, this change is attested in other languages too. Number 8 is only example, where the satem-centum change occured. The question was how to get /s/ form /k'/, the change from /k'/ to /s/ can't be dirrect as from ts > s, so which were intermediate sounds between k' > ? > ? > ? > s ? —The preceding unsigned comment was added by Roberts7 (talk • contribs) 14:23, 19 March 2007 (UTC).
I think you will find this link interesting. http://soltdm.com/langtdm/phon/palatala_e.htm. Theta in Thracian is probably the sound you are looking for. Thus equating the word Grecian = Thracian (according to this theory) If you believe in a greco-thraco-phrygian group (http://soltdm.com/langmod/romana/grecrom.htm) which I think I do, then there is a source of satemization from the north of Greece. It seems that satemization in my opinion is an external influence from the North East of the Black Sea, since we see a gradient of satemization even like "centum" languages such as greco-thraco-phrygian (that includes ancient macedonian by the way). Even Slavic (which according to new genetic evidence) originated in the Ukraine and NOT in the baltics did not escape satemization since it was closer to the North-Caucasian/Pontic source. --Kupirijo 00:00, 20 March 2007 (UTC)
Gosh. Roberts, what are you talking about? Number "8" with "two holes" appeared in Europe only in Middle Ages, what does it have to do with PIE at all? Besides, the word for "eight" comes from PIE *h₃eḱteh₃, *oḱtō, so -> Lithuanian aštuoni, Latvian astoņi. Now, as for your question, the most likely intermediate stage between the palatized velar and sibilant is an affricate, so, for example, ḱ -> ts -> s. The change ḱ -> ts, by the way, is attested even in originally non-satem languages such as Luwian. However, when establishing regular sound correspondences, you don't have to mention every single intermediate stage in the phonetic change, so there is no problem with writing ḱ -> s. Remember, it is just a sound correspondence, and not necessarily the full sound change. KelilanK 19:22, 5 May 2007 (UTC)
Ok, if we state that s < ts < ḱ (for Latvian & Slavic & Avestan?), but š < tš < ḱ (for Lithuanian) (Sanskrit has ś < ć < ḱ ), then what is common form of ḱ sound for Proto-Balto-Slavic language? As also how this ḱ was pronounced? There is really impossible to palatalize the k sound, the only existing platal versions of k are ķ [c] (actually palatalized t sound), č [tʃ] (again palatalized t only stronger than ķ) and c [ts] (also affricate (nonpalatal) from t sound), Polish has also ć [ʨ] (intermediate sound between ķ and č). Can you try to pronounce f.e. the word *aḱsis 'axis'? The only variant is [akjsjis].
By Lithuanian linguists Latvian s is usually considered to be developed from Lithuanian š (such opinion is propagated in all linguistic books about Latvian ethymology and in many other Lithuanian articles like this), because it's easier to state that Latv. asara < Lith. ašara "tear" than Latv. asara<asrā<atsrā<..<aḱrū, but Lith. ašara<ašrā<ačrā<..<aḱrū. I don't know any real attestation of such s < š and z < ž sound change. Roberts7 23:16, 7 May 2007 (UTC)
questionable material deleted
- The existence of this feature in Northwest Caucasian languages is significant, since they represent the language family that is geographically closest to the supposed Indo-European homeland in the southern Russian steppes, which, added to the poor vowel system and glottalic consonants apparently shared between PIE and NW Caucasian, hints at an early Sprachbund [2].
"this feature" is a three-way dorsal split. the glottalic theory isn't widely accepted and i suspect that this supposed sprachbund isn't, either. Benwing (talk) 04:43, 14 February 2008 (UTC)
- The material is sourced. It could be rephrased to comply to NPOV policy. I don't have any idea why a scholarly view should be widely accepted for being encyclopedic, or please find sources that reject the theory convincingly. Rokus01 (talk) 07:51, 14 February 2008 (UTC)
- You seem to completely misinterpret the WP:NPOV; read it and you'll see that fringe scientific opinions do not bear inclusion. Read glottalic theory and you'll see that it's no longer widely accepted (if it ever was). Benwing (talk) 05:30, 17 February 2008 (UTC)
Greek-Turkish graphic inaccuracy
Gosh (gulp)! The second map has the line running right across the middle of Turkey. Now, I presume that Wikipedia is not redoing the work of Mustafa Kemal and Woodrow Wilson and that no zealots are trying to start a war here. The line runs along the coast of Turkey and all parties are interested in keeing it that way, so why don't we be also? Can someone produce another map redrawing that line?Dave (talk) 05:05, 25 November 2009 (UTC)
PS. Ever listen to the radio in 1943? Along with the fishies who swam and swam all over the dam and the mares eat oats and does eat oats but little lambs eat ivy is one that goes "now it's Istanbul not Constantinople .. why did Constantinople get the works? That's nobody's business but the Turks!" sung to the tune of "puttin' on the Ritz." The map is so small scale it may not make any difference but I would say - in fact I definitley will say - definitely - Istanbul is a Turkish city and has not been Greek-speaking Constantinople since the Parthenon was blown up as an ammunition storage dump. Can we come up to date here? It does say "modern."Dave (talk) 05:18, 25 November 2009 (UTC)
Tocharian graphic inaccuracy
Although Tocharian "ain't been blue" on our map it needs to be. The discovery that it is centum is part of the reason why the isogloss can't be viewed as a nodal split of Indo-European. Whoever corrects the other map should correct this one also.Dave (talk) 09:09, 25 November 2009 (UTC)
Dravidian
In the second map, Southern India is shown as "Satem". Actually, it speaks non-Indo-European Dravidian parlance. —Preceding unsigned comment added by 86.157.178.16 (talk) 09:19, 25 November 2009 (UTC) Also, the Munda area is wrongly coloured in as Sanskritic and Satem. —Preceding unsigned comment added by 86.177.254.78 (talk) 10:55, 25 November 2009 (UTC)
Brugman 1897
"By the 1897 edition of his work, Brugmann changed his mind, accepting the centum vs. satem terminology introduced by von Badke in 1890. Accordingly, he denoted the labiovelars as qu̯, qu̯h, gu̯, gu̯h (also introducing voiceless aspirates)."
The only things right about this are Brugmann, 1897 and Brugmann changed his mind. So, I'm beefing it up a bit, Brugmann 1897 open before me on the screen.Dave (talk) 15:48, 27 November 2009 (UTC)
Gobbledeygook
"For instance, Oswald Szemerényi (e.g., in his 1995 Introduction), while recognizing the usefulness of the distinction *kʷ, *k, *ḱ as symbolizing sound-correspondences, argues that the support for three phonologically distinct rows in PIE is insufficient and prefers a twofold notation of *kʷ, *k."
This is not an instance of the creation of an artifact. "Symbolizing sound correspondences" has no meaning. And and finally, this author, who is presenting a survey, makes any kind of argument for anything, as he is trying to present all arguments. If he personally supports two rows he certainly hides it well, as we see three all over the place. It really is hard to know what he personally thinks; he may not have included that at all. He is only assessing the arguments of others, which is something we ought to be doing. Anyway this piece of prose will have to be completely rewritten. Oh yes, he does not prefer a "twofold notation." Notation refers to the symbols not the ideas. Ostensibly he prefers two rows, not the notation for two rows (except I don't believe that he does). I don't mean to be mean but if you can't talk the talk, learn it first and then don't talk it, explain it to others.Dave (talk) 00:33, 28 November 2009 (UTC)
Post mortem: the main problem with this writing is that no proper references are given. Thus we cannot check anything said except by thumbing through and trying to find where the author may have said that, succeeding only by accident. Unfortunately this deficit has led to intellectual sloppiness on the part of the editor. He does not know what the author he mentions actually said, so he makes it up, so to speak, according to his own frame of reference. We don't know what he read or whether he read anything, as he does not give enough verbal clues to say much of anything comprehensible. Sorry. This is what NOT to do on Wikipedia. Someone should have marked it early on as lacking references. Instead all of you, including at least one system administrator, thought it best to stretch out the discussion page with much opining, to use a word from the article. Opine on your own time, this is not a forum, it is an encyclopedia. Find a chat site if you want to play "little professor.".Dave (talk) 00:33, 28 November 2009 (UTC)
the war of the shadows
"The likelihood of three dorsal rows has also been disputed on typological grounds, but that argument has little merit, since there are, indeed, languages with such a three-row system, for example Northwest Caucasian languages such as Abkhaz, the Yazgulyam language (an Iranian language, but its system of dorsals is unrelated to PIE phonology), Hausa and Hopi."
No one but a linguist would have any idea at all what it means to dispute something on typological grounds. I suppose the editor means that someone said in effect, "why, you can't have a three-row system." What someone would that be, and why did he say such as thing as that? A shadow moving in the world of shadows. The shadow knows, heh, heh, heh. Shadows may know but apparently being shadows they are unable to have an effect in the real world and like Dickens' Jacob Marley must stand by and let it all happen. Dear me. I looked for this in Winifred P. Lehmann and elsewhere and found nothing. Now, if a linguist truly said that, would not this shadowy linguist also know about all these other 3-row systems? What, does the editor think they are stupid? Or is the editor presenting shadows of some shadow argument seen by him as he peers into the darkness? Maybe we will have to go into the lands of perpetual mist and snow to query the shadows ourselves! Anyway (bah) I am setting this aside for lack of references and unclarity. Generals can be unclear in their orders but not Wikipedia editors.Dave (talk) 08:34, 30 November 2009 (UTC)
False witness
"While usually reconstructed for PIE, the labiovelar quality of this row may also be an innovation of the Centum group, causally related to the depalatalization of the palatovelars. The chief witness for this question is Anatolian, the phonology of which is for orthographical reasons not known in detail. Hittite (and Luwian) did not use the existing cuneiform q- series (which stood for a voiceless uvular stop or velar ejective in Akkadian), but represents reflexes of PIE labiovelars as ku. Opinions on whether the ku represents an Anatolian single phoneme, or a group of /k+w/ are divided, but in either case Hittite lexical data support reconstructions with a labialized element."
This paragraph goes into some detail to explain the problem of orthography, which prevents us from knowing if any ku- testify to any labiovelars. But it just got through saying Anatolian was a witness to the creation of labiovelars by depalatalization of palatovelars. Which is it, difficult or a witness? I conclude it is a difficult witness and we toss them out of court. There are no references on this paragraph. We have already talked about labiovelars and depalatalization, which was a view held by Von Bradke. The origin of the labiovelars has no bearing on the centum-satem gloss. In this article, who cares where they came from? What happened to them is more to the point. All we need to say is there are a few points of view concerning where they came from and that has already been covered. Clarity is severely handicapped by the unreferenced generaliities. Once again, we are not interested in essay-type opinions or attempts to form opinions but only in the opinions presented by authoritative writers in the field, whoever that should be, and we have to say who, and where, without slanting it this way or that.Dave (talk) 11:18, 2 December 2009 (UTC)
Caucasian hypothesis
I commented this out until I finish going over the article. At this point it does not seem relevant to the Centum-Satem isogloss. Basically it presents theories of the origin of PIE consonants. Our article here, on the other hand, talks about what happened to them after the break-up. The Glottalic theory and the Caucasian Sprachbund although interesting and inadequately presented here don't have a thing to do with centum and satem that I can see. Correct me if I'm wrong. Regardless of their origin velar palatals got satemized on break-up or after or else got centumized. From that point of view who cares where they came from, whether one, two or three rows and exactly where the articulation points are and whether like Caucasian or not, as long as you have sounds becoming palatal or more palatal in one case (by any method) and pure velar (by any method) in the other. Thanks to Melchert the split has been recognized as non-nodal for some years now and in the world of wave theory and analogous changes anything is possible. All we are trying to say is, here is what happened. More on this after I finish going over the article.Dave (talk) 11:30, 30 November 2009 (UTC)
- "The existence of this feature in Northwest Caucasian languages, added to the poor vowel system and glottalic consonants apparently shared between PIE and NW Caucasian, may hint at an early Sprachbund[1] or substratum that reached geographically to the PIE homelands.[2] This same type of languages, featuring complex verbs and of which the current Northwest Caucasian languages might have been the sole survivors, was cited by Peter Schrijver to indicate a local lexical and typological reminiscence in western Europe pointing to a possible Neolithic substratum.[3]"
- I reached almost the end of the article and saw no way to use this. The Sprachbund looks good and if it were being used to explain centumization and satemization I would snatch it up. It isn't, however. The context is the evolution of the consonants that later changed from some early PIE or pre-PIE stage. As such it is not on the topic of THIS article but clearly it belongs in SOME article. We don't throw away good things here (or we try not to). The areals idea fits in with it. So, I put this here for your use and I hope you manage to use it, say in the evolution of PIE or pre-PIE. Meanwhile if I see anything like these ideas in the application of the centum-satem I will work something into the final section of the article. I'm almost done here. Basically I found the article contained excellent material but understated and with consequent hasty generalizations. Keep on plugging.Dave (talk) 20:11, 4 December 2009 (UTC)
Problem with Diachronic Map
This map is incorrect in what refers to the Iberian peninsula, since it reverses the geographical/linguistic areas. In Iberia the area presented in blue should be grey and the one in grey should be blue. In fact the one presently in blue was globaly the area of the Iberian language and Tartessian language (non-Indo-European languages), while the one presently in gray was in fact the one with Celtic and Proto-Celtic languages. See, for instance, this detailed map of the Pre-Roman Peoples and Languages of Iberia. This needs to be corrected. The Ogre 13:27, 21 December 2005 (UTC)
- The map (the upper) is just weird. There's no timestamp so I'm inclined to believe that it the present situation witch leads to some strangeness. No Portugese in Portugal. Norway and Sweden isn't covered. Scotland is excluded but Ireland is not. If you adjust for another time it won't wor either since Scotland and Ireland follow the same development. Someone really needs to correct these maps. The second, hypothetical, map have some inconsistensies too.. Like.. the areas overlapping the sea, while not covering land. Especially in Denmark and Sweden. It just looks really strang. -- Henriok 11:21, 30 August 2006 (UTC)
- By now it is obvious I am doing some serious work on this article, which it needs. I don't really have a graphics set-up on my own machine however so I'm not that familiar with WP graphics. I'm going to have to leave the map fixes to you other editors. There are many complaints; it seems that what we need for a diachronic is a more precise map with more isochrons in it and for a modern map certainly we need more precision. I would suggest full- column-width maps made very precise. This will take a graphics editor. Step up to the plate, lad, hit the ball and get the game going. Meanwhile I have tried to add qualifiers to the map captions so the public will not expect to see a precise and fully accurate map here. They expect a lot from us, too much perhaps.Dave (talk) 15:38, 27 November 2009 (UTC)
Why is Slovakia (as opposed to the Czech republic or other Slavic countries) grey on the second map? 213.47.144.254 (talk) 22:40, 15 April 2010 (UTC)
- Because the map does not show the modern distribution of the Indo-European languages, and we do not even have a real idea what kind of Indo-European dialects were spoken there in ancient times. As a rough approximation of the Iron Age distribution, in the late first millennium BC, it is reasonably accurate. Details such as the Iberian Peninsula or the British Isles (who knows how long non-IE languages survived in the area where Celtic was at least a supra-regional lingua franca, when Celtic reached northern Spain, and when it was or wasn't in use in the south either as primary or secondary language; so much can have happened; it's pointless to nitpick) do not really matter, and since the Iranian/Armenian boundary is not shown, no particular spread of Armenian is implied. The idea is only to show the general trend. --Florian Blaschke (talk)
Capitalization
Neither centum nor satem is a proper adjective (unlike, that is to say, Indo-European or Goidelic, which represent the names of peoples and countries). Most of this article is correct not to capitalize, therefore. Septentrionalis PMAnderson 21:15, 11 February 2011 (UTC)
- Use of a dash instead of a hyphen is also unsupported. I doubt whether compound adjectives should be dashed in any event; but the sources certainly don't do it here. Septentrionalis PMAnderson 13:29, 14 February 2011 (UTC)
Diacritic problem
The history section pretends to relate the sounds originally recognized by the great indogermanic linguists. It doesn't, but it can be made to, but the main problem is that those linguists used different notations for phonetic representations. I'm afraid even with WP's expanded character sets we don't cover the range. Notably lacking is the circumflex k for the palatal. What we have in there now is some unreadable characters. I don't like those, never did. I like to be able to see what I am reading. I think it is perfectly justifiable to standardize everything according to the symbols offered in our character sets, which all the other linguistics articles are using. Little boxes to me are anathematic. What I have to say about that is, little box, little box, little box, little box. You figure it out, or maybe I should put a note in here that some thoughts may not be coded correctly and appear as little boxes. Any true Wikipedian should understand and excuse that. Maybe I could sell you the downloadable thoughts. Any libraries interested? I can make you a real deal.Dave (talk) 10:14, 26 November 2009 (UTC)
I'd like to point (and excuse my ignorance) that there's "Indo-Aryan" in the map. I thought its disproved that there ever existed such a people called "Aryans". That in fact those people are called Indo-Europeans? — Preceding unsigned comment added by 209.147.224.225 (talk) 16:03, 2 June 2011 (UTC)
- Uhm, no, the existence of that group has not been disproved. The Aryans did exist most certainly, and they did call themselves that name actually (well, arya- or something, to be more precise); it's just that for reasons of PC, the term tends to be avoided, and people have settled with the really clumsy and questionable (if you stop to think that only the Indo-Aryan languages are IE in India, and that "Iran" again comes from arya-, you just can't win, i. e., get rid of the term) moniker "Indo-Iranian" – and it seems we are stuck with it, as long as people still avoid salt just because Hitler used it (excuse the sarcasm). It's just the habit to extend this name to Indo-European in general, based on now discredited etymologies, which has been abandoned. What the early Indo-European speakers called themselves, and what they were called by other people, and which term we'd adapt based on that information if we did have information about the names applied to them, is anyone's guess. We just don't know; we're stuck with another clumsy and questionable choice of term here. For the time being, I have to explain that the Indo-Aryan languages are the "Indo-Iranian languages" native to India, while the simple truth is that the Indo-Aryan languages are the Aryan languages native to India (in any definition of "Aryan", incidentally). --Florian Blaschke (talk) 21:16, 13 November 2011 (UTC)
Incorrect, politically motivated map removed...
Well I removed it.
This map is incorrect, and politically motivated. Romanian is centum, not Satem; first of all... You cannot put the boundaries making any decision on Saami, Finnish, Estonian, Hungarian and Turkish... because they aren't Indo-European.
Also, the line is completely identical (except for where it goes through Turkey) to the old boundary between communist and non-communist states...
I therefore state that it is politically motivated and should be removed from pages it is on as it is not authoritative.
Also, calling MODERN Indo-European languages satem or centum is flawed on a number of grounds. Technically that would make French and English satemized by now, as c before front vowels has shifted to s.--Yalens (talk) 17:16, 19 September 2010 (UTC)
Please remove the link to incorrect map http://upload.wikimedia.org/wikipedia/commons/thumb/0/05/Indo-European_isoglosses.png/350px-Indo-European_isoglosses.png, as this map shows South Slavonic Languages as Centum, which they aren't and Latin as not have augmentatives, which it abounds in.
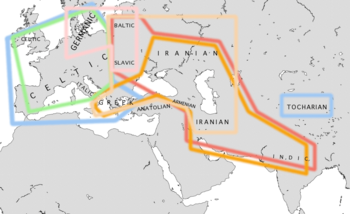{kind=link}
Ta. —Preceding unsigned comment added by 109.245.82.182 (talk) 01:36, 4 November 2010 (UTC)
- I also wonder about the pronunciation of various Hellenic/Greek variants - it's not always known, therefore should not be glossed over.--LeValley 03:08, 28 March 2011 (UTC)
- Yalens, and IP: Any map which shows the continent as dominated by Celtic languages is obviously not intending to reflect the linguistic geography of modern Europe; for reasons of convenience, such maps regularly approximate the distribution reconstructible for the Iron Age, or classical antiquity, essentially the same period.
- As for Greek and modern Indo-European languages, secondary palatalisations are irrelevant when it comes to the centum/satem isogloss; Greek, Italic and Germanic are clearly centum. Also, English has NOT shifted c to s, not in its native vocabulary at least; it's a pronunciation rule borrowed from French. (Technically, there was a secondary palatalisation in English, as well, in fact already in Old English, but it shifted Proto-West-Germanic *k to ch, and similarly *g to y, sometimes even dg.) Moreover, augments and augmentatives are two completely different things. --Florian Blaschke (talk) 21:31, 13 November 2011 (UTC)
Some basics that would make this article more readable
In most Wikipedia articles, there are phonetic guides on how to pronounce the terms.
How is Centum pronounced? Sintum? tsintum? Kentum? Anyone want to venture a guess on explaining this?
How is Satem pronounced (almost rhymes with Satam, except for the final consonant) or Sah-teem?
Makes a huge difference to the comprehensibility of the article.--LeValley 03:07, 28 March 2011 (UTC)
- [kentum] (it's Latin) and [satem] (it's Avestan), more or less. But these are just convenient labels for the sound changes. --Taivo (talk) 04:51, 28 March 2011 (UTC)
- Or approximately KEN-toom (with a short vowel like u in put) and SAH-tum (actually, the ah is short, too) for those who don't know IPA. --Florian Blaschke (talk) 21:35, 13 November 2011 (UTC)
Third map
In the third map from the top, "Anatolian" seems to be excluded from all six areas. —Preceding unsigned comment added by 86.177.254.83 (talk) 12:29, 3 June 2010 (UTC)
- That's intentional, actually, not a mistake. Anatolian is just weird. --Florian Blaschke (talk) 21:38, 13 November 2011 (UTC)
Polyphyletic or Paraphyletic or
If all Indo-Europeans fall into the two categories centum and satem, it isn't possible for both groups to be paraphyletic according to the usual meaning of the word. Does it have a different meaning for linguistics, did one or the other page mean polyphyletic, or is there simply a mistake?
Answer: Yes, you are right! And which is more, the view that the satəm languages are polyphyletic is only one of two possibilities that are under discussion. My opinion is that they are monophyletic. And e.g. close relation between German and Slavic is surely a result of secondary processes, not evidence for their relationship.
Because the matter has not been univocally solved so far, my suggestion is to delete the appropriate statement from the article. What do you think about it?
BTW. Some modern centum languages are formally satəm in fact. See French cent [sã] which has [s] in the place of the original (Latin) [k]. Even if it is a result of secondary development, the division into kentum (centum) and satem must be taken with caution.
--Grzegorj 11:55, 9 May 2005 (UTC)
- I remove the statement because I agree with you.--Wiglaf 07:34, 13 May 2005 (UTC)
- Centum languages with secondary palatalization of /k/ to /s/ are not in any way "formally satem in fact". In French cent /sã/, /s/ goes back to PIE
- /ḱ/, true enough; but in cinq /sɛ̃k/ it goes back to PIE */kw/. And
- /ḱ/ shows up as /k/ in cœur /køːʁ/. --Angr/tɔk tə mi 21:42, 22 July 2005 (UTC)
- It is not true at all. They are just 3 examples which can prove nothing. In fact, PIE *k and *k' merged long before Classic Latin times. *kw was a separate phoneme but sometimes the labialization was reduced (like in quinque > cinq). There is no reason to get back to the PIE times hence French developed from Latin, not immediately from PIE. Latin lost the difference PIE *k' : *k and French was not able to restore it in any way.
- The development of Latin [k] and [kw] in French depended on the phonetic environment, not on its deeper etymology. Namely, [k] developed into [ts] and eventually into [s] before a front vowel (ex. merci from mercēdem, or cent /sã/ from centum /kentum/), into [tš] and eventually into [š] before [a] (ex. Charles from Carolus, chose from causam etc.), and stayed unchanged in other positions (ex. coude from cubitum [k], aucun from alicūnum etc.).
- And, the process of changing of former (Latin) [k] into [s] before a front vowel is what caused the numeral "100" to begin from [s] in French, just like in satəm languages. Because we know Latin, the language from which French developed, we can say that [s] in French word for "10" is secondarily. But if we had not known the language which gave birth to French, we would not have been able to say whether French is centum or satəm. French is formally satəm because the word for "100" begins with [s] in this language. Of course we could count this language as centum but it is so only because we have additional knowledge.
- So, if we had known that ex. a Dacian word for "100" begins with [s], it would not have been the ultimate argument yet that Dacian belongs to the satəm group. It is so because it might have been secondarily satemized just like French.
- --Grzegorj 20:23, 4 August 2005 (UTC)
- If we didn't know about Latin and only had French, we could still not arrive at the conclusion that it is a satem language on the basis of cent alone, as there are words like cœur which still show the centum reflex. --Florian Blaschke (talk) 21:48, 13 November 2011 (UTC)
Question
Where does Albanian fall into? At the beginning of the article it is stated that it's satem, and yet by the end of the article Albanian ends up being neither satem nor centum. The word for 100 in Albanian is 'qind' which is very close to the sound of k/c-int of centum. ~~Xhamlliku~~
Xhamlliku, Albanian 'qind' most likely is a loan from Latin 'centum'. This is what most linguists theorize, because 'qind' is not the expected form from PIE *(d)k'm.-tom.
11 sept. 'qind' sounds more like an influence from Italian 'cento'. Albanian use "zet" example 'njëZET' or 'dyZET' which reminds the original word 'sat(em)'. Mostly the difference is clear is some specific words like:
English 'god':
German 'Gott'(G) which is centum, compared to Albanian 'Zot'(Z) which is satem. The difference is G ~ Z. Centum ~ Satem.
- No, qind is generally accepted as a Latin loanword. The sound changes after the period of the Latin borrowings are well understood, and the palatalisation here is secondary and has nothing to do with Italian. An Italian loanword would sound much closer to Italian, even basically identical to Italian, as there haven't been a lot of sound changes (probably no relevant ones, at least) in the past few centuries. --Florian Blaschke (talk) 21:53, 13 November 2011 (UTC)
Tocharian and Albanian
As far as I know, Tocharian is unambiguously Centum. The palatovelars and plain velars are merged. Keeping the labiovelars distinct is not a necessary condition for being called Centum, as merging the labiovelars with the plain velars could have happened at any time (it happened between Primitive Irish and Old Irish, for example). As for Albanian, I don't know much more about it than what I've read in Beekes, but it seems clearly Satem: the palatovelars have become the dental fricatives th, dh, while the plain velars and labiovelars largely merged. Beekes says the evidence that plain velars did not (secondarily) palatalize to s before front vowels while labiovelars did is "too meagre". So the strongest evidence is that Albanian is straightforwardly Satem. --Angr/tɔk tə mi 12:19, 5 September 2005 (UTC)
Well, Albanian is mostly Satem, and for the purposes of dealing with Albanian, we can say it is Satem, no problem, but the mostly becomes essential when looking at the areal nature of Satemization (I admit, of course, that in no family was Satemization 100.000% complete, so yes, we can call Albanian Satem as long as the exceptions are noted). As for Tocharian, my point is that there is no evidence of any connection, areal or otherwise with the western Centum group. Tocharian simply melted all dorsal rows together, which really amounts to a 'null' status. Phonematically, you may as well call it Satem (palatovelars and velars collapsed), although of course the affrication is missing. I argue that evidence of labiovelars but not palatovelars at some stage is required for a Centum language. In the case of Tocharian, there possibly was such a stage, but we simply don't know. In Irish, even if we didn't have Primitive Irish, we could argue from the difference in treatment of gw and g that the labiovelars were, at some stage, separate. If we didn't have any such evidence in Celtic, I agree the situation would be just like in Tocharian. We do, however, have this evidence for Celtic, but not for Tocharian. dab (ᛏ) 13:26, 5 September 2005 (UTC)
PS, I realize that non-usage of the cuneiform "q" series by Hittite is a weak argument; they didn't use voiced vs voiceless either, and Semitic 'emphatic' stops are not equal to IE labiovelars. The Romans did still adopt Phoenician q for their labiovelar. Anyway, the main point there is that since Hittite doesn't spell its labiovelars as "q", there is no evidence either way. dab (ᛏ) 13:32, 5 September 2005 (UTC)
- In Andrew Sihler's New Comparative Grammar of Greek and Latin he argues that there is no Centum grouping, that Centum is simply a cover term for those languages that did not undergo Satemization. Under that definition Tocharian is clearly Centum by virtue of being non-Satem. But Sihler's definition of Centum (which he probably lifted from somewhere without citing his sources, something that irritates me no end about that book) of course doesn't have to be the only definition of Centum. As for Q in Latin, they didn't borrow Q to stand for their labiovelar, exactly; their labiovelar was spelled QV. And they probably didn't borrow it directly from Phoenician at all, they probably borrowed it from Greek qoppa, which was sometimes used in inscriptions to indicate a backed allophone of /k/ before /u/. --Angr/tɔk tə mi 14:22, 5 September 2005 (UTC)
- agreed on both counts. I will correct the Latin labiovelar to qv. Yes, we should make clearer that while the Satem group is a result of "Satemization", the Centum group is often taken to equal "non-Satem". Since Albanian and Armenian are Satem on the surface, and that they may have been satemized secondarily not more a suspicion, Centum/Satem was indeed an 'either or' classification in Brugmanns time. It is precisely the 'outer' languages, Toch. and Anatolian, that require us to reevaluate the term. Still, logically, there was something like a "Centumization". Either, if there were three rows, a merger of k and k', or if there were only two rows, the (phonetic) creation of a labiovelar row. Clearly then, centum/satem cannot be a logical either/or term, because if the PIE phonology had survived in some remote pocket, it would be neither. Looking at the proto language of each branch, it is very clear that Italic/Germanic/Greek/Celtic were Centum, and that BSl/IIr was Satem. It is unclear whether Proto-Anatolian was either, and it is unclear what happened to Tocharian. If we apply Brugmann's "centum = non-satem" of course they will be centum, but that does not give any insight. Progress lies in the realization that centum/satem is a classification of "inner" dialects. dab (ᛏ) 06:00, 6 September 2005 (UTC)
- I think it is not even clear that Latin has labiovelar phonemes. Latin_spelling_and_pronunciation#Summary_of_phonemes gives gw and kw, but I suppose their monophonemic status is dubitable. I'm not sure about this, I suppose one has to decide from metrical evidence. dab (ᛏ) 06:08, 6 September 2005 (UTC)
- According to Allen & Greenough's New Latin Grammar, qu, gu, and su counted as single consonants for metrical purposes. I'd hate to conclude on that basis that Latin had a phoneme /sʷ/, though. --Angr/tɔk tə mi 06:44, 6 September 2005 (UTC)
- As far as I know, labiovelars are assumed for Proto-Tocharian in all recent reconstructions, and for Proto-Italic as well (the labiovelars having changed to plain labials in Sabellic, but I don't know if a cognate of equus is attested anywhere in Sabellic – it could help settle the question). Any later developments are insubstantial. Intermediate protolanguages are awesome – people should use them more, much more. --Florian Blaschke (talk) 22:01, 13 November 2011 (UTC)
- According to Allen & Greenough's New Latin Grammar, qu, gu, and su counted as single consonants for metrical purposes. I'd hate to conclude on that basis that Latin had a phoneme /sʷ/, though. --Angr/tɔk tə mi 06:44, 6 September 2005 (UTC)
Dacian and Romanian
Why not the Dacian suta (plural sute)? Why should be the Dacian language extinct? Romanian is by far more vivid and rich to be of Latin origin. Jacob Stirbu
The name satem (or correctly: satəm) is taken from Avestan for historical reasons. It was just an arbitrary decision.
The question why Dacian should be extinct is not clear. But it IS extinct! Romanian has got only few words from the pre-Roman substratum (i.e. from Dacian). But it is not a topic to be placed within the "Satem" subject.
--Grzegorj 11:54, 9 May 2005 (UTC)
Actually Grzegorj, Romanian has a very large quantity of substratum words, the only real debate is whether they are Dacian---or Thracian, or Illyrian, et cetera. Alexander 007 04:21, 19 July 2005 (UTC)
- Oh... I am not a Romanist so I do not know the exact number. But A. Cihac in his etymological dictionary of Romanian gives 2350 Slavic words (of course all of them are borrowings), 1150 Latin words, 950 Turk words, 650 Greek words, 600 Hungarian words and only 50 "Albanian" ones (some of them may be Dacian, Thracian or Illyrian). Maybe later studies let scholars find more Balkanisms in Romanian. Nevertheless, 50 of the total amount of 5750 means ca. 8.5 pro mille (not even 1%). I would not rather say that it is a very large quantity...
- --Grzegorj 20:23, 4 August 2005 (UTC)
- Frankly, your source was wrong. The cognates (not loans) between Albanian and Romanian alone number about 145 (I take this number from a Hungarian source that was discussing the issue). Add to that the words of unknown etymology/origin that are not found in Albanian, and your figure and your characterization is completely wrong. Alexander 007 20:30, 4 August 2005 (UTC)
- OK, I have cited a source from 19th century. Some of dark Romanian words may be Bastarnan or even Sarmatian. But please, even 200 Balkanian words give only 3% of all the vocabulary. So, it is not "a very large quantity", do not exaggerate. Compare it with the amount of native (Latin) words: they are 6 times more. And all the Romanian grammar is Romance with Slavic influence, not Dacian. So, we should forget Dacian. Dacian is extinct! Only some Dacian words may have survived. Just like some Gaul words have survived in French.
- --Grzegorj 21:32, 4 August 2005 (UTC)
- 19th century etymological dictionaries dealing with Romanian are known to be outdated and full of errors. As a rule, they tend to have slighted any notion of a large substratum element, and in retrospect this tendency to underestimate was a tendency based on 19th century psychology rather than science. I agree that Dacian is extinct, and I agree we must not just assume a Dacian substratum. But there is a Balkanic substratum in Romanian, whether "Dacian", "Moesian", "Thracian", or "Illyrian". I may or may not have exaggerated when I said very large quantity, but note that I have in mind a figure around 300, and I consider that a very large quantity when one is speaking of substratum words. The linguist/Thracologist Sorin Olteanu in his LTDM site says there may be thousands [3]. I do not claim thousands, and I'm not sure how he arrived at that figure (I think he was considering Aromanian as well), but I do claim around 300; quite a number of linguists would agree. Alexander 007 21:41, 4 August 2005 (UTC)
What Jacob was asking was "Why not list Dacian 'suta' among the examples of words for hundred that show the Satem sound-change?". He wasn't asking "Why not change the artice's name to 'suta'?" To answer his question: we can't list Romanian 'suta' as Dacian because it is not attested as Dacian. Though not attested as Dacian, a number of current linguists are accepting that Romanian 'suta' is not from Slavic 'sto', but more likely from the substratum. Alexander 007 04:31, 19 July 2005 (UTC)
- Why not form Slavic? But the Slavic word for "100" was nothing else but *suta! During centuries the former short a developed regularly into o in Slavic, and short u developed into the ultra-short vowel marked with Russian "hard sign", ъ. So, the oldest attested Slavic (Old Church Slavic) word for "100" was sъto. It shows 100% accordance with the Romanian form. And I see virtually no reason for searching another source for the Romanian word.
--Grzegorj 20:23, 4 August 2005 (UTC)
- Despite what you see, and you are entitled to your opinion (nor am I diminishing this particular opinion of yours), current linguistic sources no longer assume a Slavic origin for sutǎ. See even the conservative DEX (it is online [4] ), which does not derive it from Slavic. Unless I'm mistaken (I haven't read the detailed studies), the problem is that by the time the Slavs influenced Romanian, they no longer had the word in the form *suta (unattested), so Romanians were not likely to get it from them. You seem to be interested in this, so I will pass on what linguistic references I can find on this topic onto your Talk Page eventually if not here. I would imagine though that "Slavic" (excuse the generalization) references would still assume that the Romanian word is a loan. Alexander 007 20:37, 4 August 2005 (UTC)
- But it is not true what you say, be more exact for the future. "SÚT//Ă1 ~e num. card. 1) Nouăzeci plus zece. O ~ de pagini. 2) cu valoare de num. ord. Al sutălea; a suta. /<sl. suto"
- So, DEX does derive the word from Slavic! So do I. Please give evidence that I am wrong, not trends.
- The Slavs were able to influence Romanian very early, even before their migration to the Balkan Peninsula. But some Slavic tribes were north-eastern neighbours of Proto-Romanians as early as at the very beginning of the Middle Age. And the form *suta may have survived up to ca. 800 AD. The evidence is the phonetic shape of old Slavic loans in Greek. I do not think that the first Slavic-Romanian contact was later that the Slavic-Greek one. So, I do not think that those who refuse Slavic origin of sutǎ are specialists in the early history of the Slavs. Of course, they may be right but only if they know another possible and more probable source. Frankly, I do not think that any such source exists.
- --Grzegorj 21:47, 4 August 2005 (UTC)
- You have quoted NODEX, and the bibliography does not indicate [5] that it is published by the Academia Romana, which is more official. The DEX, which the bibliography notes is published by the Academy, gives the source as unknown (Et. nec.). Alexander 007 21:53, 4 August 2005 (UTC)
- Negative view ("unknow source") means no view. Please show why the word cannot be of Slavic origin. I cannot see such evidence.
--Grzegorj 23:34, 4 August 2005 (UTC)
- When the DEX states Et. nec., it indicates that the source of the word is unknown. This means that those linguists at the Academy (who are conservative, mind you, and in most cases they will rather say a word is from Slavic than say it is of unknown origin) as of 1998 did not accept the Slavic origin. Why? Well, I'm not in Romania, so I do not have much access to the references in question. The NODEX from 2002 does not seem to be published by the Academy, though it is a Romanian publication also, and it gives a supposed Slavic origin for the word. Alexander 007 01:14, 5 August 2005 (UTC)
Sorin Olteanu: The reason why they reject, on good ground, the slavic etymology is the accent: while in slavic the stress falls on the final syllable (sŭtó), in Rom. if falls on the first, the word being pronounced sútă (like in eng. soóter). For other issues visit my site http://soltdm.tripod.com/index.htm
- That's a very questionable argument; I doubt that it is widely accepted. Grzegorj is completely right with his assertions. --Florian Blaschke (talk) 21:44, 13 November 2011 (UTC)
- In fact, the argument makes no sense at all. Romanian does not have and has never had a free accent, unlike Slavic, so the stress in Romanian sútă is necessarily on the first syllable; it cannot even possibly be on the final syllable as in Early Slavic *sutá.
- Slavic *sutá with the *u reflex for the syllabic nasal is completely unique; even within Slavic, that reflex, instead of the expected *simtá, is totally irregular (perhaps it is due to influence from Iranian *satám). No other Indo-European language has a word for "hundred" like that, or could be predicted to have one. Even for Thracian, Dacian or other ancient Balkan languages I have never seen anyone assume a reflex of any syllabic nasal like that. A rejection of Slavic origin for the Romanian word requires incredibly special pleading.
- Moreover, this would not be the only plausible early Slavic borrowing in Romanian (and Albanian, by the way). A further well-known example is Romanian baltă (and Albanian baltë) "swamp", which is best explained as a loanword from Slavic *balta > OCS blato prior to the liquid metathesis, which cannot be shown to be older than the close of the 8th century. Such Slavic words with essentially Baltic vocalism could probably be borrowed as late as the beginning of the 9th century, even. --Florian Blaschke (talk) 01:39, 15 November 2011 (UTC)
Map nonsense
The map contradicts all scholarly insights into the development of IE languages since over half a century, which are relatively well explained in the article and thus needs urgently to be removed. Here the otherwise well-informed user seems to have confused a lot of things. In particular the map mistakenly suggests an original kentum-satem division, albeit perhaps not meant as thus. E.g. is Armenian the next neighbour to Greek, as is Albanian (c.f. e.g. Meier-Brügger L339 and many others).HJJHolm (talk) 15:09, 7 July 2012 (UTC)
Not sure I follow
So, you have labiovelars, velars, and palatovelars (or are they just palatals?). In centum, the palatovelars merge into the velars, so you wind up with velars and labiovelars. In satem, the labiovelars merge into the velars, so you wind up with velars and palatovelars. OK. So where on Earth are all the fricatives coming from? (satem, not ḱatem.) Did this lenition happen in all the satem languages? Is it part of 'satemisation', or does that word only describe the stop journey? Could the article be amended for more legibility, please?
- The precise original phonetic realisation of the dorsals in PIE is unclear. The palatovelars could have been true palatovelar (palatalised velar, such as [kʲ], as in Russian) or palatal consonants (notated as [c] in IPA). However, the acoustic difference is not great; I'm not sure if any languages even contrast both. There's even a voiced pre-velar stop mentioned in Voiceless palatal stop. All satem languages reflect the "palatal" row as some kind of affricate or fricative (probably always sibilant), but the velar reflex [k] in kentum languages makes it extremely unlikely that they were original affricates or fricatives, that's why an original stop articulation is assumed (that was changed into some kind of affricate or fricative later). Strictly speaking, the affrication/fricativisation is not a necessary part of the definition. The merger of labiovelars (via delabialisation) into the plain velars is much more characteristic, as it is a change that affected the structure of the phonological system, unlike the affrication/fricativisation (although even here there is doubt whether the delabialisation happened particularly early in all branches, as there are possible traces of the distinction virtually everywhere). Also, palatalisation (but also delabialisation) happened secondarily even in kentum branches (for example in many Romance languages, or in Tocharian, and similarly also in Phrygian and even Greek). The single most distinctive and unambiguous change is the merger of the "palatal" and the "pure/plain velar" row (whatever their original realisation was) in the kentum languages. --Florian Blaschke (talk) 17:33, 29 January 2015 (UTC)
Satemization
Dab, I call satemization interesting, because it implies important historic upheavels- tied to horse and chariot like theorized by Robert Drews- attested by a satem language changing process that originated in an (already Indo-Iranian) central steppe region and radiated to influence many other IE languages, leaving out some remarkabable exceptions on the fringes (like Tocharian). Secondary satemization has been theorized and described concerning Balto-Slavic languages (loosely linked to Germanic), and I am interested in gathering similar information published on Albanian (satem, nevertheless linked to "centum" Illyrian and especially Messapian) and on Armenian (satem, somehow closely linked to "centum" Greek features). Even Greek did not escape Indo-Iranian influence in an early stage, although it didn't receive enough to "satemize". Obviously, "satemization" drew new boundaries along natural barriers splitting up old communities. The impact of satemization can be traced back a lot easier than the changes implied by centum, of which most information is irretrievably lost. The mechanism has been repeatedly suggested or assumed, however, most information on this topic is dispersed and specialized. I think it will justify a focus but, since it involves a lot more than linguistics, rather in a separate article. Rokus01 20:35, 2 March 2007 (UTC)
- Note that several scholars now think that Balto-Slavic is completely satem and exceptions are explainable from a regular lack of palatalisation in certain contexts, especially directly before resonants (also found in Albanian and Armenian, and before /r/ even in Indo-Iranian, where it is known as Weise's law), and Germanic loanwords (this is the best way to account for the fact that the Baltic word for "goose" shows the regular satem development and the Slavic word shows the kentum reflex). This is certainly the most satisfying approach. --Florian Blaschke (talk) 18:15, 29 January 2015 (UTC)
removal
The existence of this feature in Northwest Caucasian languages - a language family that might have reached geographically to the Indo-European homelands -, added to the poor vowel system and glottalic consonants apparently shared between PIE and NW Caucasian, may hint at an early Sprachbund[4] as substantiated in 1995 by Marek Zvelebil in his Neolithic creolisation hypothesis. Likewise, linguist Peter Schrijver speculates on the reminiscent lexical and typological features of a family of languages featuring complex verbs, of which the Northwest Caucasian languages might have been the sole survivors.[3]
I have removed the text highlighted above, for the following reasons: a) The "Neolithic creolization hypothesis" is completely unrelated to Kortland's view as expressed in his paper(reference 1), so that while the first sentence is talking apples, the second is talking oranges. It would be confusing to keep the two. b) This article is ultimately about just one aspect of Indo-European phonology, not about the prehistory of Indo-Europeans, so that one reference to a hypothesized Sprachbund should be more than enough.KelilanK (talk) 12:57, 14 July 2008 (UTC)
- You are right about B (this might be better somewhere else), though you have to understand that as soon as geographic distribution becomes important, this will need some contextual information or footnote, also here.
- Concerning A: Apples and oranges together make fruit. Likewise, working on an encyclopedia involves compiling related information. As long this compiled information tegether doesn't intend to create new arguments and SYN, like here, this is perfectly valid.
- On this basis, I would like to hear your arguments as to why you think Kortlandt's Sprachbund proposal involving NW Caucasic languages does not belong to the same category as Peter Schrijver's research on reminiscent "NW Caucasian"-like influences on languages in Western Europe, and the Neolithic creolisation theory that describes the prehistoric conditions towards the hypothetized sprachbund that might have facilitated this feature in more detail.
- Rokus01 (talk) 14:00, 14 July 2008 (UTC)
The Neolithic Creolization Hypothesis favors the "Broad homeland" hypothesis, the idea of a vast dialect continuum and is essentially based on archeology. It does not necessarily involves contacts with the Caucasus area - perhaps even on the contrary, it may be incosistent with the idea of a particularly close contact with NW Caucasian as opposed to multifarious "hunter-gatherer" groups. Kortlandt's view, on the other hand, is strictly grounded in linguistic typology and shared phonological features. His paper makes no reference to to the NCH, and it would constitute original research to merge both hypotheses into a single "applorange". As for the mention of Schrijver's research, it could be readded after a bit of rewriting, sure (i.e., it should be restated briefly), but I still think that we shouldn't give undue weight to these theories in an article about something as specific as the Centum-Satem isogloss of IE. Having a reference to Kortlandt's paper in passing would do, methinks...KelilanK (talk) 14:53, 14 July 2008 (UTC)
- Ok, it was not my intention to merge different underpinning hypotheses. Kortlandt wrote his piece in advance of NCH and clearly based himself to the Steppe theory, while Peter Schrijver took into consideration a kind of Neolithic Non-IE(!) "Wave of Advance", that might have reached the Caucasus as well as western Europe: basically to identify the linguistic substrate. NCH would in my interpretation be compatible to both. Instead, the key question that should emerge here is: Did this particular type of substrate work on PIE, or separate on each evolving branch? Schrijver suggests that the process may have been local in western Europe. This requires a little tweak, from "a language family that might have reached geographically to the Indo-European homelands" to "a language family of which the Northwest Caucasian languages might have been the sole survivors, that would have reached geographically to the European homelands as well as to western Europe where, according to Peter Schrijver, such kind of languages featuring complex verbs left a local lexical and typological reminiscence." Rokus01 (talk) 15:53, 14 July 2008 (UTC)
- Schrijver's hypothesis has nothing to do with Kortlandt's at all. Kortlandt proposes contact between (ancestors of) Proto-Indo-European and Proto-Northwest-Caucasian in the steppes north of the Caucasus in the Neolithic (in order to explain the fact that the closest morphological agreement of Proto-Indo-European appears to be with Proto-Uralic while the closest typological/phonetical resemblance is with Northwest Caucasian instead), while Schrijver proposes contact of individual Indo-European branches (mainly Germanic, Celtic, Italic and Greek) with an unknown language family which appears to have resembled Northwest Caucasian (as well as Hattic and Minoan) typologically, within Central and Southeastern Europe in the Bronze and Iron Ages, especially in the drainage basin of the Danube. This unknown substratum family he identifies with the languages of the first farmers in Europe, who immigrated from Anatolia to Southeastern Europe and via the Danube to Central Europe. Kortlandt's proposed contact happened much farther east, and much earlier, than Schrijver's, and among quite different languages. Also, Schrijver never suggests that the Northwest Caucasian languages are strictly related to the first-farmers substrate; he just provides them as an example of the structural type that the substrate seems to have. The Northwest Caucasian languages are not the sole remnant of the proposed substratal family, but of the structural type it represents, which Schrijver suggests was formerly much more widespread in western Eurasia. (Proto-Indo-European was not really of the same type, as its phonological system is less complex and it does not exhibit complex verbs with polypersonal agreement, for example, nor definite articles.) --Florian Blaschke (talk) 19:02, 29 January 2015 (UTC)
"Centumization followed by satemization" doesn't make sense
"It is therefore clear that centumization was followed by satemization."
This doesn't make any sense. Centumization means the merger of the palatovelars with the plain velars; satemization means the merger of the plain velars with the labiovelars. In a language that has undergone centumization there is no longer a plain velar class distinct from the palatovelars, so the merger of such a class with the labiovelar series is impossible. Can this paragraph be revised or removed? — Preceding unsigned comment added by 50.1.48.24 (talk) 04:38, 16 June 2014 (UTC)
- I've marked the sentence you quoted as needing clarification. The rest of the paragraph is salvageable; it's just this one sentence, and I don't understand it either. However, it may be an issue of what is meant by "satemization" and "centumization" respectively. I suspect that the account is simply confused and what is meant here by "centum" is that the distinction between plain velars and labiovelars was originally present in satem languages as well. But lack of "satemization" in this sense doesn't mean "centum", nor can it be described as "centumization" when nothing has happened and the original distinction is instead preserved. PIE was neither "centum" or "satem" by definition, so prior to the satem-type merger, the later satem languages weren't either: as stated above, the assibilation isn't part of "satemization", strictly speaking, but rather incidental. --Florian Blaschke (talk) 17:56, 29 January 2015 (UTC)
For ease of reference, here is the paragraph under discussion:
The Centum–Satem isogloss is now understood to be a chronological development of Proto-Indo-European. Centumization removed the palatovelars from the language, leaving none to satemize. In addition there is residual evidence of various sorts in satem languages of a former distinction between velar and labiovelar consonants, indicating the earlier centum state. It is therefore clear that centumization was followed by satemization. However the evidence of Anatolian indicates that centum was not the original state of Proto-Indo-European.
It is terrible, and in some points even factually wrong.
- "satemization" is the collapse of velars and labiovelars; this is sub-phonematically accompanied by an assibilation of the palatovelars, yes, but the distinctive feature is the loss of the labviovelar row.
- "centumization" is the collapse of palatovelars with velars.
- both "satemization" and "centumization" can only happen to a dialect close enough to PIE to preserve all three rows. Once a row has been lost, it is misleading to use these terms. Thus, "leaving none to satemize" is an abuse of terminology. E.g. French would be "satemized" Latin in this terminology, but this is not how we describe French. French doesn't enter into this.
- "It is therefore clear that centumization was followed by satemization" is not a valid conclusion of "satemization may not have been 100% complete".
- "the evidence of Anatolian indicates that centum was not the original state of Proto-Indo-European" — I have no idea what this is supposed to mean. Of course "centum" was not the "original state", because "centum" means "there are no palatovelars" and not "there are labiovelars". But even if you wanted to argue that "PIE was centum", i.e. "there was no palatovelar row in PIE", Anatolian evidence would not in the least prevent you from doing that. People keep messing this up, and I don't know what else to do to prevent the re-introduction of this confusion.
- there is no logical dichotomy of "a language is either centum or satem". Any branch may in principle be neither, because the parent language was neither. There is, in fact, good evidence that some languages are neither, including Albanian, Anatolian and Tocharian. Just because Tocharian collapsed all three rows it does not follow that it was either "satemized" or "centumized". It may or may not have been, but that information has been lost by subsequent changes.
In conclusion, avoid at any cost the suggestion that this is an "either-or" scenario. The core centum group is Italo-Celtic-Germanic-Greek, and the core satem group is Balto-Slavic-plus-Indo-Iranian. Outside of these, the other branches can well be discussed for their affinity to either group, but this needs to be done with care and closely based on specific references. Avoid sweeping claims like "Tocharian is centum" or "Albanian is satem" even if you have a reference saying exactly that: you should do so because there is a subtle debate on these branches going on, and it will not do to summarize such a debate by just quoting some random (even if scholarly) soundbite.
Also avoid suggesting that the "isogloss has been dismissed". It has not: it is still an isogloss, even an important one. Yes, it is not a tree-like, phylogenetic division, but IE studies has been well aware that the early history of IE languages is not tree-like for at least a century now, so could Wikipedia please stop treating this truism as if it was breaking news? It's an isogloss even if it isn't monophyletic. Pointing out that it isn't monophyletic is completely uncontroversial and no big deal needs to be made of how this is "current" opinion, because the opinion has been widely held for more than a century now. Better to focus on more recent alternative proposals and their reception. --dab (𒁳) 11:10, 12 September 2015 (UTC)
Why centum-satem?
Why is it called centum-satem, given that these examples don't really show what is going on? — Preceding unsigned comment added by 82.139.82.82 (talk) 08:30, 8 July 2015 (UTC)
- Because the whole article is nonsense and not written by professional Indo-Europeanists, who since 50 years do no longer use this feature for subgrouping. This is one phonological shift of many others, which probably took place independently (note that present-day French underwent a "Satemization", too).
Some laymen appear to be very much unteachable.217.93.145.38 (talk) 09:38, 28 November 2015 (UTC)
Article rename proposal
An isogloss is specifically a [i]geographical[/i] boundary dividing areas on the basis of a linguistic feature.
Although the Centum-satem isogloss is an interesting and important topic related to the Centum-satem division in the Indo-European language family, this article A) is not mainly about the isogloss, but is instead about the Centum-satum division itself but B) is the only major article related to the Centum-satem division.
I propose that this article be renamed Centum-satum division and that a discussion of the isogloss be included as a small section within this article.
Ordinary Person (talk) 01:44, 19 January 2013 (UTC)
- Despite it now being three years old, I would support this proposal (or perhaps even better, call it centum and satem languages). W. P. Uzer (talk) 22:50, 19 November 2015 (UTC)
- Since there is no objection, I will do this latter move. If anyone in fact objects, we can discuss the best title. W. P. Uzer (talk) 09:00, 4 December 2015 (UTC)
External links modified
Hello fellow Wikipedians,
I have just modified one external link on Centum and satem languages. Please take a moment to review my edit. If you have any questions, or need the bot to ignore the links, or the page altogether, please visit this simple FaQ for additional information. I made the following changes:
- Added archive https://web.archive.org/web/20100709201329/http://www.linguistics.ucla.edu/people/Melchert/The%20Position%20of%20Anatolian.pdf to http://www.linguistics.ucla.edu/people/Melchert/The%20Position%20of%20Anatolian.pdf
When you have finished reviewing my changes, please set the checked parameter below to true or failed to let others know (documentation at {{Sourcecheck}}).
This message was posted before February 2018. After February 2018, "External links modified" talk page sections are no longer generated or monitored by InternetArchiveBot. No special action is required regarding these talk page notices, other than regular verification using the archive tool instructions below. Editors have permission to delete these "External links modified" talk page sections if they want to de-clutter talk pages, but see the RfC before doing mass systematic removals. This message is updated dynamically through the template {{source check}} (last update: 18 January 2022).
- If you have discovered URLs which were erroneously considered dead by the bot, you can report them with this tool.
- If you found an error with any archives or the URLs themselves, you can fix them with this tool.
Cheers.—InternetArchiveBot (Report bug) 13:47, 18 November 2016 (UTC)
Phonetic correspondences table -- should modern languages have modern or (reconstructed) historical forms in the table
I don't know as much about Armenian, but I'm not sure how to handle Albanian in the table (and Armenian obviously is going to have the same issue). I just cleaned up some stuff that was factually wrong (claimed palvelar k' went to th and then s, that's backwards). But should the table be showing the modern correspondences in Albanian (and Armenian) or what they are postulated to have been at the relevant time period as the other languages in the table? In the case of Albanian as per Orel it would have been /ts/ or /s/ in Early Albanian which overlaps with the Roman period, not th. Perhaps @Florian Blaschke: has an idea about this? --Yalens (talk) 21:11, 27 July 2017 (UTC)
External links modified
Hello fellow Wikipedians,
I have just modified one external link on Centum and satem languages. Please take a moment to review my edit. If you have any questions, or need the bot to ignore the links, or the page altogether, please visit this simple FaQ for additional information. I made the following changes:
- Added archive https://web.archive.org/web/20090216042336/http://popgen.well.ox.ac.uk/eurasia/htdocs/anderson.html to http://popgen.well.ox.ac.uk/eurasia/htdocs/anderson.html
When you have finished reviewing my changes, you may follow the instructions on the template below to fix any issues with the URLs.
This message was posted before February 2018. After February 2018, "External links modified" talk page sections are no longer generated or monitored by InternetArchiveBot. No special action is required regarding these talk page notices, other than regular verification using the archive tool instructions below. Editors have permission to delete these "External links modified" talk page sections if they want to de-clutter talk pages, but see the RfC before doing mass systematic removals. This message is updated dynamically through the template {{source check}} (last update: 18 January 2022).
- If you have discovered URLs which were erroneously considered dead by the bot, you can report them with this tool.
- If you found an error with any archives or the URLs themselves, you can fix them with this tool.
Cheers.—InternetArchiveBot (Report bug) 05:22, 2 August 2017 (UTC)
- ^ Kortlandt 1993, p. 3.
- ^ Kortlandt, Frederik (1989). "The spread of the Indo-Europeans" (PDF).
- ^ a b Schrijver, Peter (2007). "Keltisch en de buren: 9000 jaar taalcontact" (PDF). University of Utrecht.
{{cite web}}: Unknown parameter|month=ignored (help) Cite error: The named reference "Schrijver" was defined multiple times with different content (see the help page). - ^ [6] Frederik Kortlandt-GENERAL LINGUISTICS AND INDO-EUROPEAN RECONSTRUCTION, 1993