e-Aksharayan is an optical character recognition engine for Indian languages. Some of research work from e-Aksharayan has been published in different conferences and journals.[2][3][4][5]
| Written in | C++ |
|---|---|
| Operating system | Linux (32 & 64-bit), Windows (32-bit) |
| Available in | Interface: English Recognition: Assamese, Bengali, Bodo, Devanagari, Kannada, Gujarati, Gurumukhi, Oriya, Malayalam, Meitei, Marathi, Tamil, Telugu, Tibetan and Urdu |
| Type | Optical character recognition |
| Website | ocr |

Screenshots
edit-
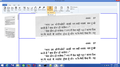 OCR output for Devanagari
OCR output for Devanagari -
 OCR output for Devanagari OCR output for Devanagari, sync between image and output
OCR output for Devanagari OCR output for Devanagari, sync between image and output -
 OCR output for Devanagari OCR output for Devanagari, spell checker
OCR output for Devanagari OCR output for Devanagari, spell checker



References
edit- ^ e-Aksharayan home page
- ^ Greedy Search for Active Learning of OCR Greedy Search for Active Learning of OCR
- ^ Text graphic separation in Indian newspapers Text graphic separation in Indian newspapers
- ^ An OCR System for the Meetei Mayek Script An OCR System for the Meetei Mayek Script
- ^ Experiences of Integration and Performance Testing of Multilingual OCR for Printed Indian Scripts Experiences of Integration and Performance Testing of Multilingual OCR for Printed Indian Scripts
External links
edit
This software article is a stub. You can help Wikipedia by expanding it. |